[정보처리기사] 정보처리기사 외울 것
정보처리기사 실기 대비 외워야할 것들 정리

문제 풀이 중 외울 것 정리
복구
- RTO (Recovery Time Objective)
- 시간 측면에서의 목표 (중단 시점부터 얼마나 빨리 서비스 정상화를 할 것인가)
- RPO (Recovery Point Objective)
- 데이터 측면에서의 목표 (장애가 발생했을 때 어느 시점으로 데이터를 복원할 것인가, 즉 허용 가능한 데이터 손실 범위)
DCL
- COMMIT
- 데이터의 조작 결과를 최종적으로 반영할 때 사용하는 언어
- ROLLBACK
- 데이터의 조작 내역을 이전으로 돌릴 때 사용하는 언어
OSI 7계층
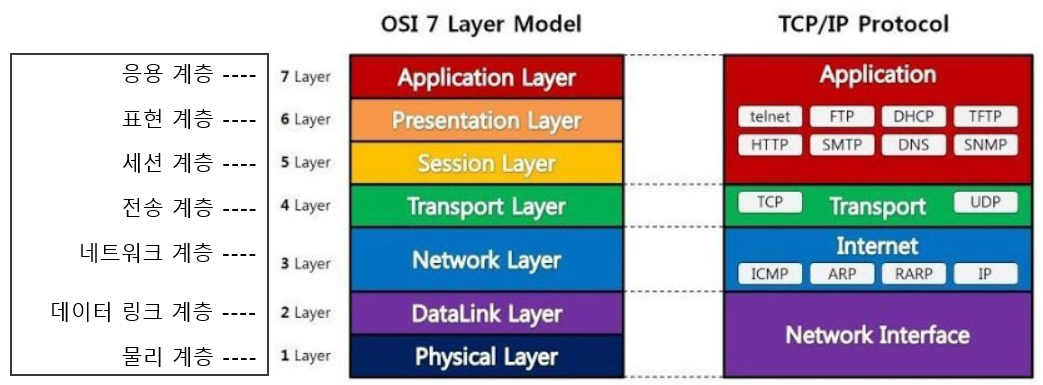
- (7 Layer, Application Layer) 응용 계층
- 응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행하는 역할을 담당하는 계층
- (6 Layer, Presentation Layer) 표현 계층
- 서로 다른 데이터 표현 형태를 갖는 시스템 간의 상호 접속을 위해 필요한 계층으로, 코드 변환, 데이터 암호화, 데이터 압축, 구문 검색 등의 기능을 수행하는 계층
- (5 Layer, Session Layer) 세션 계층
- 응용 프로그램 간의 대화를 유지하기 위한 구조를 제공하고, 이를 처리하기 위해 프로세스들의 논리적인 연결을 담당하는 계층
- (4 Layer, Transport Layer) 전송 계층
- 상위 계층들이 데이터 전달의 유효성이나 효율성을 생각하지 않도록 해주면서, 종단 간의 사용자들에게 신뢰성 있는 데이터를 전달하는 계층
- (3 Layer, Network Layer) 네트워크 계층
- 개발 시스템들 간의 네트워크 연결을 관리하며, 경로 제어, 패킷 교환, 트래픽 제어 등의 기능을 수행하는 계층
- ICMP
- TCP/IP 기반의 인터넷 통신 서비스에서 인터넷 프로토콜(IP)과 조합하여 통신 중에 발생하는 오류 처리와 전송 경로의 변경 등을 위한 제어 메시지를 취급하는 무연결 전송용 프로토콜
- ICMP
- 개발 시스템들 간의 네트워크 연결을 관리하며, 경로 제어, 패킷 교환, 트래픽 제어 등의 기능을 수행하는 계층
- (2 Layer, Data Link Layer) 데이터 링크 계층
- 물리적으로 연결된 두 개의 인접한 개방 시스템들 간에 신뢰성 이고 효율적인 정보 전송을 할 수 있도록 연결, 설정, 데이터 전송, 오류 제어 등의 기능을 수행하는 계층
- (1 Layer, Physical Layer) 물리 계층
- 실제 장치들의 전기적, 물리적 세부 사항들을 정의하는 계층
UI
- 직관성
- 누구나 쉽게 이해하고 사용할 수 있어야 한다.
- 유효성
- 사용자의 목적을 정확하고 완벽하게 달성해야 한다.
- 학습성
- 누구나 쉽게 배우고 익힐 수 있어야 한다.
- 유연성
- 사용자의 요구사항을 최대한 사용하고 실수를 최소화해야 한다.
LOD (Linked Open Data)
- 정의
- 웹상에 존재하는 데이터를 개별 URI(Uniform Resource Identifier)로 식별하고, 각 URI에 링크 정보를 부여함으로써 상호 연결된 웹을 지향하는 모형이다. 링크 기능이 강조된 시맨틱 웹의 모형에 속한다고 볼 수 있으며, 팀 버너스 리의 W3C를 중심으로 발전하고 있다.
- 주요 기능
- 공개된 데이터를 이용하면 내가 원하는 데이터가 이미 존재하는지, 어디에 존재하는지를 알 수 있다.
- URI로 구별되는 데이터 리소스의 자유로운 접근 및 이용이 가능하므로 큰 노력 없이 데이터의 매쉬업이 가능하다.
- 내가 만든 데이터가 아니라도 URI를 이용하여 링크만 해주면 이용할 수 있다.
- 4대 원칙
- 통합 자원 식별자(URI)를 사용한다.
- URI는 HTTP 프로토콜을 통해 접근할 수 있어야 한다.
- RDF나 스파클 같은 표준을 사용한다.
- 풍부한 링크 정보가 있어야 한다.
- Linked Data와 Open Data를 결합한 용어이다.
DB 관련
데이터 모델의 구성 요소
- 연산 (Operation)
- 데이터베이스에 저장된 실제 데이터를 처리하는 작업에 대한 명세로서 데이터베이스를 조작하는 기본 도구에 해당한다.
- 구조 (Structure)
- 논리적으로 표현된 객체 타입들 간의 관계로서 데이터의 구성 및 정적 성질을 표현한다.
- 제약 조건
- 제약 조건은 데이터베이스에 저장될 수 있는 실제 데이터의 논리적인 제약 조건을 의미한다.
DB 구축 단계
- 요구 사항 분석
- 개념적 설계
- 논리적 설계
- 물리적 설계
- DB 구현
스키마 3계층
스키마란? 데이터베이스의 구조와 각종 제약 조건을 기술한 논리적 청사진
- 외부 스키마
- 논리적 구조 정의, 사용자 뷰
- 사용자가 근하는 뷰에 해당하며, 데이터베이스의 일부분만을 보여줌
- 개념 스키마
- 전체적인 논리적 구조
- 데이터베이스의 전체적인 논리적 구조를 정의하며, 모든 사용자에게 공통적으로 보이는 뷰
- 내부 스키마
- 데이터를 물리적으로 저장하는 방식을 정의하며, 데이터베이스 시스템 내부에서 사용됨
- 물리적 저장장치 관점을 어떻게 배열할지에 대한 내용
Join
- 세타 조인
- 조인에 참여하는 두 릴레이션의 속성 값을 비교하여 조건을 만족하는 튜플만 반환하는 조인
- 동등 조인
- 세타 조인에서
=연산자를 사용한 조인으로, 일반적으로 조인이라고 동등 조인을 의미 - 동등 조인의 결과 릴레이션의 차수는 첫 번째 릴레이션과 두 번째 릴레이션의 차수를 합한 것
- 세타 조인에서
- 자연 조인
- 동등 조인의 결과 릴레이션에서 중복된 속성을 제거하여 수행하는 연산
- 즉, 동등 조인에서 중복 속성 중 하나가 제거된 것
- 핵심은 두 릴레이션의 공통된 속성을 매개체로 하여 두 릴레이션의 정보를 “관계”로 묶어 내는 것
관계대수 연산자
- 순수 관계 연산자
- 셀렉션 (Selection, σ): 릴레이션에서 조건을 만족하는 행(Tuple, 데이터)을 선택
- 프로젝션 (Projection, 𝜋): 릴레이션에서 특정 열(Attribute, 속성)만 추출
- 조인 (Join, ⨝): 두 릴레이션을 공통 속성을 기준으로 결합
- 디비전 (Division, ÷): R 테이블이 S 테이블의 모든 튜플과 연관된 R 테이블의 요소를 추출
- 일반 집합 연산자
- 합집합 (Union, ⋃): 두 릴레이션의 모든 튜플을 합침
- 교집합 (Intersection, ⋂): 두 릴레이션의 공통 튜플만 추출
- 차집합 (Difference, −): R 테이블에 존재하지만 S 테이블에는 없는 튜플을 추출
- 카티션 곱 (Cartesian Product, ×): 두 릴레이션의 모든 조합 생성
관계해석
- 관계 데이터의 연산을 표현하는 방법으로, 관계 데이터 모델의 제안자인 코드(E. F. Codd)가 수학의 술어 해석(Predicate Calculus)에 기반을 두고 관계 데이터베이스를 위해 제안했다.
- 원하는 정보가 무엇이라는 것만 정의하는 비절차적 특성을 지니며, 원하는 정보를 정의할 때 계산 수식을 사용한다.
- 튜플 해석식을 사용하는 튜플 관계해석과 도메인 해석식을 사용하는 도메인 관계해석으로 구분된다.
즉각 갱신 기법 (Immediate Update)
- 트랜잭션이 데이터를 변경하면 트랜잭션이 부분 완료되기 전이라도 즉시 실제 DB에 그 내용을 반영하는 기법이다.
- 장애가 발생하여 회복 작업할 경우를 대비하여 갱신된 내용들을 로그(Log)에 보관시킨다.
- 즉각 갱신 기법에서 회복 작업을 수행할 경우 Redo와 Undo 모두 수행이 가능하다.
테스트
화이트박스 테스트 검증 기준 ⭐
- 문장 검증 기준 (Statement Coverage)
- 문장 1회
- 모든 문장이 한 번 이상 실행된다.
- 분기(결정) 검증 기준 (Decision Coverage)
- T/F
- 분기점은 조건문에서의 각 분기 또는 논리적 분기 지점을 나타내고, 각 분기는 프로그램의 특정 경로를 나타내며, 조건문의 참/거짓에 따라 결정된다.
- 모든 코드 분기가 테스트되었을 때 100%의 분기 커버리지가 달성된다.
- 조건 검증 기준 (Condition Coverage)
- T/F, F/T
- 각 조건이 참과 거짓으로 평가되는 모든 가능한 경우를 테스트한다.
- 각 조건이 최소한 한 번은 참으로, 한 번은 거짓으로 평가되도록 한다.
- 분기/조건 기준 (Condition Devicion Coverage)
- T/T, F/F
- 프로그램의 모든 분기점이 최소한 한 번 실행되었는지를 나타낸다.
- 모든 코드 분기가 테스트되었을 때 100%의 분기 커버리지가 달성된다.
- 프로그램의 모든 조건이 참과 거짓으로 평가되었는지를 나타낸다.
- 각 조건을 만족하거나 만족하지 않는 경우를 테스트하여 100%의 조건 커버리지를 달성한다.
- MC/DC (Modified Condition / Decision Coverage)
- 개별 조건식이 다른 개별 조건식의 영향을 받지 않고 전체 조건식의 결과에 독립적으로 영향을 주는 구조적 테스트 케이스이다.
- 해당 개별 조건식이 전체 조건식의 결과에 영향을 주는 조건 조합을 찾아 커버리지를 테스트하는 방법이다.
- 프로그램에 있는 모든 결정 포인트 내의 전체 조건식이 적어도 한 번은 참과 거짓을 만족해야 한다.
- 프로그램에 있는 결정 포인트 내의 모든 개별 조건식이 적어도 한 번은 참과 거짓을 만족해야 한다.
블랙박스 테스트 종류
- 동치 분할 검사 (Equivalence Partition)
- 입력 자료에 초점을 맞춰 테스트 케이스를 만들고 검사하는 방법
- 원인-효과 그래프 검사 (Cause-Effect Graph)
- 입력 데이터 간의 관계와 출력에 영향을 미치는 상황을 체계적으로 분석
- 오류 예측 검사 (Error Forecast)
- 과거의 경험이나 감각으로 테스트하는 기법이며, 보충적 검사 기법
- 비교 검사 (Comparison Testing)
- 동일한 테스트 자료를 여러 버전의 프로그램에 입력하여 동일한 결과가 출력되는지 테스트하는 기법
- 경계값 분석 (Boundary Value Analysis)
- 입력 조건 경계값에서 오류 발생 확률이 크다는 것을 활용하여 경계값을 테스트 케이스로 선정하여 검사
테스트 오라클
- 참 오라클
- 모든 테스트 케이스 입력값의 기대한 결과값에 대한 확인
- 가능한 모든 전수 테스트 가능
- 샘플링 오라클
- 특정 입력값들에 대해서만 원하는 결과를 제공해주는 오라클
- 전수 테스트가 불가능한 경우에 사용
- 경계값, 구간별 예상값 결과 작성에 사용
- 휴리스틱 오라클
- 샘플링 오라클의 단점 개선을 위해 특정 몇몇 입력은 샘플링 오라클과 같은 결과 제공, 나머지 입력은 휴리스틱(확률과 직관) 처리
- 실험 결과나 수치 데이터 처리 시 사용
- 일관성 검사 오라클
- 이전 수행 결과와 현재 수행 결과가 동일한지 검증
- 회귀 테스트에서 수정 전/후의 결과 확인 또는 비교 시 사용
UML
UML은 시스템 분석, 설계, 구현 등 시스템 개발 과정에서 시스템 개발자와 고객 또는 개발자 상호 간의 의사소통이 원할하게 이루어지도록 표준화한 대표적인 객체지향 모델링 언어로, 사물, 관계, 다이어그램으로 이루어져있다.
- 관계는 사물과 사물 사이의 연관성을 표현하는 것으로, 연관, 집합, 포함, 일반화 등 다양한 형태의 관계가 존재한다.
- 클래스는 UML에 표현되는 사물의 하나로, 객체가 갖는 속성과 동작을 표현한다. 일반적으로 직사각형으로 표현하며, 직사각형 안에 이름, 속성, 동작을 표기한다.
- 인터페이스는 클래스와 같은 UML에 표현되는 사물의 하나로, 클래스나 컴포넌트의 동작을 모아 놓은 것이며, 외부적으로 가시화되는 행동을 표현한다. 단독으로 사용되는 경우는 없으며, 인터페이스 구현을 위한 클래스 또는 컴포넌트와 함께 사용된다.
네트워크
연결성 VS 비연결성
- 가상 회선 (Virtual Circuit, TCP)
- 연결성 통신에서 주로 사용되는 방식으로, 출발지와 목적지의 전송 경로를 미리 연결하여 논리적으로 고정한 후 통신하는 방식
- 데이터그램 (Datagram, UDP)
- 비연결형 통신에서 주로 사용되는 방식으로, 사전에 접속 절차를 수행하지 않고 페더에 출발지에서 목적지까지의 경로 지정을 위한 충분한 정보를 붙여서 개별적으로 전달하는 방식
프로토콜
- 프로토콜은 서로 다른 기기들 간의 데이터 교환을 원할하게 수행할 수 있도록 표준화시켜 놓은 통신 규약이다.
- 프로토콜의 기본 3요소
- 구문 (Syntax)
- 의미 (Semantics)
- 시간 (Timing)
- 경로 제어 프로토콜 (Routing Protocol)
- 경로 제어 프로토콜은 크게 자율 시스템 내부의 라우팅에 사용되는 IGP(Interior Gateway Protocol)와 자율 시스템 간의 라우팅에 사용되는 EGP (Exterior Gateway Protocol)로 구분할 수 있다.
- IGP는 소규모 동종 자율 시스템에서 효율적인 RIP와 대규모 자유 시스템에서 많이 사용되는 OSPF로 나누어진다.
- OSPF는 링크 상태(Link State)를 실시간으로 반영하여 최단 경로로 라우팅을 지원하는 특징이 있다.
- BGP (Border Gateway Protocol)는 EGP의 단점을 보완하여 만들어진 라우팅 프로토콜로, 처음 연결될 때는 전체 라우팅 테이블을 교환하고, 이후에는 변화된 정보만을 교환한다.
OSPF의 특징
- RIP의 단점을 해결하여 새로운 기능을 지원하는 인터넷 프로토콜이다.
- 인터넷 망에서 이용자가 최단 경로를 선정할 수 있도록 라우팅 정보에 노드 간의 거리 정보, 링크 상태 정보를 실시간으로 반영하여 최단 경로로 라우팅을 지원한다.
- 대규모 네트워크에서 많이 사용된다.
- 최단 경로 탐색에 Dijkstra 알고리즘을 사용한다.
- 라우팅 정보에 변화가 생길 경우 변화된 네트워크 내의 모든 라우터에 알린다.
- 링크 스테이트 라우팅 알고리즘을 사용하며, 하나의 자율 시스템(AS)에서 동작하면서 내부 라우팅 프로토콜의 그룹에 도달한다.
애드 혹 네트워크 (Ad-hoc Network)
- 재난 및 군사 현장과 같이 별도의 고정된 유선망을 구축할 수 없는 장소에서 모바일 호스트(Mobile Host)만을 이용하여 구성한 네트워크이다.
- 망을 구성한 후 단기간 사용되는 경우나 유선망을 구성하기 어려운 경우에 적합하다.
- 멀티 홉 라우팅 기능을 지원한다.
NAT (Network Address Translation)
- 한글로 번역하면 네트워크 주소 변환이라는 의미의 영문 3글자 약자이다.
- 1개의 정식 IP 주소에 다량의 가상 사설 IP 주소를 할당 및 연결하는 방식이다.
- 1개의 IP 주소를 사용해서 외부에 접속할 수 있는 노드는 어느 시점에서 1개만으로 제한되는 문제가 있으나, 이 때에는 IP 마스커레이드(Masquerade)를 이용하면 된다.
IPC (Inter-Process Communication)
- 모듈 간 통신 방식을 구현하기 위해 사용되는 대표적인 프로그래밍 인터페이스의 집합으로, 복수의 프로세스를 수행하며 이뤄지는 프로세스 간 통신까지 구현이 가능하다.
- 대표적인 메소드에는 공유 메모리(Shared Memory), 소켓(Socket), 세마포어(Semaphores), 파이프와 네임드 파이프(Pipes & named Pipes), 메시지 큐잉(Message Queueing)이 있다.
접근 통제
- MAC (Mandatory Access Control, 강제적 접근 통제)
- 주체, 객체 등급 기반 접근 권한 부여
- 자원의 보안 레벨과 사용자의 보안 취급 인가를 비교하여 접근 제어를 한다.
- 어떤 주체가 어떤 객체에 접근하려 할 때 양자의 보안 레벨(보안 등급)을 비교한다.
- 높은 보안을 요하는 정보가 낮은 레벨의 주체에게 노출되지 않도록 접근을 제한하는 방법이다.
- DAC (Discretionary Access Control, 임의적 접근 통제)
- 접근 주체 신분 기반 접근 권한 부여
- 접근 주체가 속해 있는 그룹의 신원에 근거하여 객체에 대한 접근을 제한하는 방법이다.
- 자원의 소유자가 접근을 요청하는 사용자의 식별자를 확인하여 객체에 대한 접근을 통제하는 방법이다.
- RBAC (Role-Based Access Control, 역할 기반 접근 통제)
- 주체, 객체 역할 기반 권한 부여
- 주체와 객체가 어떻게 상호작용하는지 결정하기 위해 중앙에서 관리되는 통제 모음을 사용한다.
- 어떤 주체가 적절한 역할(Role)에 할당되고 역할에 적합한 접근 권한이 할당된 경우만 객체에 접근할 수 있는 방법이다.
- 비임의적 접근제어(Non DAC)로 전통적인 MAC, DAC의 대체 수단으로 사용된다.
보안
암호화 알고리즘 ⭐️
- 양뱡향
- 대칭키
- DES, TDES, AES, IDEA, ARIA, OPT, RC4, A5/1
- 비대칭키
- RSA, Rabin, DSA, DH, Elgamal, ECC(이산대수 활용), ECDSA
- 대칭키
- 단방향
- Hash
- MD5, SHA-1, SHA-2
- Hash
- IDEA (International Data Encyption Algorithm)
- 스위스의 라이(Lai)와 메시(Messy)는 1990년 PES를 발표하고, 이후 이를 개선한 IPES를 발표했으며, IPES는 128비트의 Key를 사용하여 64비트 블록을 암호화하는 알고리즘이다.
- Skipjack
- 국가 안전 보장국(NSA)에서 개발한 암호화 알고리즘으로, 클리퍼 칩(Clipper Chip)이라는 IC 칩에 내장되어 있으며, 80비트의 Key를 사용하여 64비트 블록을 암호화하며, 주로 전화기와 같은 음성 통신 장비에 삽입되어 음성 데이터를 암호화한다.
공격 기법
- 사회 공학 기법
- 컴퓨터 보안에 있어서, 인간 상호 작용의 깊은 신뢰를 바탕으로 사람들을 속여 정상 보안 절차를 깨트리기 위한 비기술적 시스템 침입 수단을 의미한다.
- 다크 데이터
- 특정 목적을 가지고 데이터를 수집하였으나, 이후 활용되지 않고 저장만 되어있는 대량의 데이터를 의미한다.
- 미래에 사용될 가능성을 고려하여 저장 공간에서 삭제되지 않고 보관되어 있으나, 이는 저장 공간의 낭비뿐만 아니라 보안 위험을 초래할 수 있다.
- 세션 하이재킹 (Session Hijacking)
- 세션을 가로채다라는 의미로, 정상적인 연결을 RST 패킷을 통해 종료시킨 후 재연결 시 희생자가 아닌 공격자에게 연결하는 공격 기법이다.
- TCP 세션 하이재킹은 공격자가 TCP 3-Way-Handshake 과정에 끼어듦으로써 서버와 상호 간의 동기화된 시퀀스 번호를 갖고 인가되지 않은 시스템의 기능을 이용하거나 중요한 정보에 접근할 수 있게 된다.
- Watering Hole
- 목표 조직이 자주 방문하는 웹 사이트를 사전에 감염시켜 목표 조직의 일원이 웹 사이트에 방문했을 때 악성 코드에 감염시킨 후, 감염된 PC를 기반으로 조직의 중요 시스템에 접근하거나 불능으로 만드는 등의 영향력을 행사하는 웹 기반 공격이다.
- 스니핑(Sniffing)에 대한 개념
- 네트워크의 중간에서 남의 패킷 정보를 도청하는 해킹 유형의 하나로 수동적 공격에 해당한다.
- Typosquatting
- 네티즌들이 사이트에 접속할 때 주소를 잘못 입력하거나 철자를 빠뜨리는 실수를 이용하기 위해 이와 유사한 유명 도메인을 미리 등록하는 것으로, URL 하이재킹(Hijacking)이라고도 한다.
- 유명 사이트들의 도메인을 입력할 때 발생할 수 있는 온갖 도메인 이름을 미리 선점해 놓고 이용자가 모르는 사이에 광고 사이트로 이동하게 만든다.
- Rootkit
- 시스템에 침입한 후 침입 사실을 숨긴 채 백도어, 트로이목마를 설치하고, 원격 접근, 내부 사용 흔적 삭제, 관리자 권한 획득 등 주로 불법적인 해킹에 사용되는 기능들을 제공하는 프로그램들의 모음이다.
- 자신 또는 다른 소프트웨어의 존재를 감춰줌과 동시에 허가되지 않은 컴퓨터나 소프트웨어의 영역에 접근할 수 있게 하는 용도로 설계되었다.
- 이 프로그램이 설치되면 자신이 뚫고 들어온 모든 경로를 바꾸어 놓고, 명령어들을 은폐해 놓기 때문에 해커가 시스템을 원격에서 해킹하고 있어도 이 프로그램이 설치되어 있는 사실 조차 감지하기 어렵다.
- 공격자가 보안 관리자나 보안 시스템의 탐지를 피하면서 시스템을 제어하기 위해 설치하는 악성 프로그램으로, 운영체제의 합법적인 명령어를 해킹하여 모아놓았다.
- 운영체제에서 실행 파일과 실행 중인 프로세스를 숨김으로써 운영체제 검사 및 백신 프로그램의 탐지를 피할 수 있다.
- APT
- 다양한 IT 기술과 방식들을 이용해 조직적으로 특정 기업이나 조직 네트워크에 침투해 활동 거점을 마련한 뒤 때를 기다리면서 보안을 무력화시키고 정보를 수집한 다음 외부로 빼돌리는 형태의 공격으로, 일반적으로 공격은 침투, 검색, 수집, 유출의 4단계로 실행된다.
- 침투(Infiltration) : 목표로 하는 시스템을 악성코드로 감염시켜 네트워크에 침투한다.
- 검색(Exploration) : 시스템에 대한 정보를 수집하고 기밀 데이터를 검색한다.
- 수집(Collection) : 보호되지 않은 시스템의 데이터를 수집하고, 시스템 운영을 방해하는 악성코드를 설치한다.
- 유출(Exfiltration) : 수집한 데이터를 외부로 유출한다.
- ‘침투(침입)→검색→수집→유출’의 과정을 통해 특정 조직에 고도로 정교한 기술(Advanced)로 은밀히 잠복(Persistent)하며 지속적으로 위협(Threat)을 가하기 때문에 ‘고도의 지속적 위협(Advanced Persistent Threat, APT)’
- 다양한 IT 기술과 방식들을 이용해 조직적으로 특정 기업이나 조직 네트워크에 침투해 활동 거점을 마련한 뒤 때를 기다리면서 보안을 무력화시키고 정보를 수집한 다음 외부로 빼돌리는 형태의 공격으로, 일반적으로 공격은 침투, 검색, 수집, 유출의 4단계로 실행된다.
- Smurf, Smurfing
- IP나 ICMP의 특성을 악용하여 엄청난 양의 데이터를 한 사이트에 집중적으로 보냄으로써 네트워크를 불능 상태로 만드는 공격 방법 이다.
- 공격자는 송신 주소를 공격 대상지의 IP 주소로 위장하고 해당 네트워크 라우터의 브로드캐스트 주소를 수신지로 하여 패킷을 전송하면, 라우터의 브로드캐스트 주소로 수신된 패킷은 해당 네트워크 내의 모든 컴퓨터로 전송된다.
- 해당 네트워크 내의 모든 컴퓨터는 수신된 패킷에 대한 응답 메시지를 송신 주소인 공격 대상지로 집중적으로 전송하게 되는데, 이로 인해 공격 대상지는 네트워크 과부하로 인해 정상적인 서비스를 수행할 수 없게 된다.
네트워크 보안
- SIEM (Security Information & Event Management)
- 다양한 장비에서 발생하는 로그 및 보안 이벤트를 통합하여 관리하는 보안 솔루션으로, 방화벽, IDS, IPS, 웹 방화벽, VPN 등에서 발생한 로그 및 보안 이벤트를 통합하여 관리함으로써 비용 및 자원을 절약할 수 있는 특징이 있다.
- 또한 보안 솔루션 간의 상호 연동을 통해 종합적인 보안 관리 체계를 수립할 수 있다.
- Trustzone
- 칩 설계 회사인 QRM(Advanced RISC Machine)에서 개발한 기술로, 하나의 프로세서(Processor) 내에 일반 애플리케이션을 처리하는 일반 구역(Normal World)과 보안이 필요한 애플리케이션을 처리하는 보안 구역(Secure World)으로 분할하여 관리하는 하드웨어 기반의 보안 기술이다.
ISMS(정보보호 관리체계, Information Security Management System)
- 정보 자산을 안전하게 보호하기 위한 보호 절차와 대책이다.
- 조직에 맞는 정보보호 정책을 수립하고, 위험에 상시 대응하는 여러 보안 대책을 통합 관리한다.
- 공공 부문과 민간 기업 부분에서 이것을 평가하고 인증하는 사업을 한국인터넷진흥원(KISA)에서 운영 중이다.
스케줄링
선점 스케줄링
- SRT (Shortest Remaining Time)
- 가장 짧은 시간이 소요되는 프로세스를 먼저 수행시킨다.
- 비선점 SJF를 선점 형태로 변경한 기법으로, 선점 SJF라고도 한다.
- 특징
- 더 짧은 처리시간의 프로세스가 들어오면 실행 중인 프로세스라도 중단시키고 더 짧은 처리시간의 프로세스를 처리한다.
- 준비상태 큐에 있ㄴ느 프로세스들의 실행 시간을 추적하여 보유하고 있어야 하므로 오버헤드가 증가한다.
- 긴 작업은 SJF보다 대기 시간이 길어진다.
- RR (Round Robin)
- FCFS 기법을 선점 형태로 변형한 기법이다.
- 시분할 시스템(Time Sharing System)을 위해 고안된 방법이다.
- 할당되는 시간이 작을 경우에 문맥 교환을 위한 오버헤드가 증가하며, 할당되는 시간이 클 경우, FCFS 기법과 동일하다.
- 방법
- 준비상태 큐에 먼저 들어온 프로세스가 먼저 CPU를 할당 받는다.
- 프로세스가 시간 할당량(Time Slice, Quantum) 동안 실행된 후 작업이 완료되지 않으면 다음 프로세스에 CPU를 넘겨주고 준비상태 큐의 맨 뒤로 이동한다.
- MLQ (Multi-Level Queue, 다단계 큐)
- 프로세스를 여러 그룹으로 나누어 여러 개의 다른 준비상태 큐를 사용하는 스케줄링 기법이다.
- 각 준비상태 큐는 자기만의 스케줄링을 가지고 있으므로 각 그룹의 특성에 따라 다른 방식의 스케줄링 기법을 사용할 수 있다.
- 준비상태 큐에 있는 프로세스를 실행하는 중이라도 상위 단계 큐에 작업이 들어오면 상위 단계에 CPU를 할당해야 한다.
- 그룹별 준비상태 큐의 프로세스들은 다른 준비상태로 이동할 수 없다.
- 우선순위 (높은 순)
- 시스템 프로세스
- 대화형 프로세스
- 편집 프로세스
- 일괄처리 프로세스
- MFQ (Multi-level Feedback Queue, 다단계 피드백 큐)
- MLQ/MQ에서 그룹별 준비상태 큐에서 프로세스가 큐 사이를 이동할 수 있도록 개선한 방법이다.
- 작업을 처리하는데 시간이 적은 프로세스에 유리하다.
- 상위 단계의 준비상태 큐일수록 우선순위가 높고 시간 할당량이 적다.
- 하위 준비상태 큐에 있는 프로세스 실행 중에 사우이 상태의 프로세스가 들어오면 상위 단계 프로세스에 CPU를 할당한다.
- 마지막 단계 큐에서는 작업이 완료될 때까지 라운드 로빈 스케줄링을 사용한다.
- 방법
- 준비상태 큐마다 서로 다른 할당 시간을 부여하여 완료하지 못한 프로세스는 다음 단계의 준비상태 큐로 이동하게 한다.
비선점 스케줄링
FCFS (First Come First Service, 선입선출)
FIFO(First In First Out) = queue
- 가장 간단한 기법으로, 대기 큐에 도착한 순서에 따라 CPU를 할당받는다.
- 먼저 들어온 프로세스가 먼저 처리가 되어 공평성이 유지된다. (선착순)
- 다른 기법들에 비해 완료시간 예측이 용이하다.
- 중요하지 않은 작업이 중요한 작업을, 긴 작업이 짧은 작업을 기다리게 할 수 있다.
- SJF (Shortest Job First, 단기 작업 우선)
- 준비상태 큐에서 기다리고 있는 프로세스 중에서 실행 시간이 가장 짧은 프로세스가 CPU를 할당받는다.
- FCFS보다 평균 대기시간은 감소되지만, 큰 작업에서는 FCFS보다 예측이 어렵다.
- 가정 적은 평균 대기 시간을 제공하는 최적 알고리즘이다.
- 짧은 작업을 요구하는 측면에서는 유리한 스케줄링이다.
- 실행 시간이 긴 프로세스는 실행 시간이 짧은 프로세스에 밀려 무한 연기가 될 수 있다.
- SRT와 SJF의 차이점
- SRT는 자신보다 실행시간이 작은 프로세스가 들어오면 자신까지 멈추고 그 프로세스를 먼저 처리한다.
- SJF는 자신을 처리하고 난 후에 실행 시간이 작은 프로세스를 다음으로 처리한다.
- HRN (Highest Response-ratio Next)
- 우선순위 계산식: (대기시간 + 서비스 시간) / 서비스 시간
- 실행시간이 긴 프로세스에게 분리한 SJF 기법을 보완하기 위한 스케줄링 기법으로, 대기 시간과 실행 시간을 활용한다.
- 한 프로세스가 작업을 실행하면 작업이 완료될 때까지 실행된다.
- 우선순위 계산을 통해 실행 시간이 짧은 프로세스나 대기시간이 긴 프로세스에게 우선순위를 준다.
- 실행시간이 짧거나 대기시간이 긴 프로세스일 경우, 우선순위가 높아진다.
- 기한부 (Deadline)
- 프로세스에게 일정 시간을 할당하여 그 시간 안에 작업을 완료하도록 하는 기법
- 시간 내에 작업을 완료하지 못할 경우, 제거가 되거나 처음부터 다시한다.
- 프로세스 실행 시 집중적으로 요구되는 자원관리 떄문에 오버헤드가 발생한다.
- 여러 프로세스가 동시에 실행되면 스케줄링이 복잡해진다.
- 우선순위 (Priority)
- 준비상태에서 우선순위를 부여하며 가장 높은 우선순위의 프로세스에 CPU를 할당한다.
- 우선순위가 동일할 시 FCFS 기법을 이용한다.
- 가장 낮은 순위를 받은 프로세스는 무한 연기 또는 기아 상태가 발생할 수 있다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.