[정보처리기사] 정보처리기사 필기 오답노트 3
정보처리기사 필기 대비 암기를 위한 오답노트 (2021.08.14 CBT)

1과목 - 소프트웨어 설계
럼바우(Rumbaugh) 객체지향 분석 기법
객체 모델링
- 시스템 내의 주요 객체(실세계의 개념이나 엔티티)를 정의하고, 이 객체들 간의 속성, 연관성, 상속 관계 등을 표현
- 객체 모델링은 클래스(객체) 다이어그램을 통해 객체들의 구조를 나타냄
동적 모델링
- 객체들이 시간에 따라 어떻게 상호작용하고 변화하는지 표현
- 객체의 상태 변화, 이벤트 처리 등을 포함하며, 주로 상태 다이어그램을 사용하여 시스템의 동작을 정의
기능 모델링
- 시스템에서 발생하는 함수나 연산을 모델링
- 주로 자료 흐름도(DFD)를 통해 입력과 출력 데이터를 나타내고, 프로세스 간의 데이터 흐름을 시각화함
2과목 - 소프트웨어 개발
인터페이스 구현 검증 도구
- xUnit
- JAVA(Junit), C++(Cppunit)m .Net(Nunit)와 같이 다양한 언어를 지원하는 단위 테스트 프레임워크
- STAF
- 서비스 호출 및 컴포넌트 재사용 등 다양한 환경을 지원하는 테스트 프레임워크
- 테스트 대상 분산 환경에 데몬을 사용
- FitNesse
- 웹 기반 테스트 케이스 설계, 실행, 결과 확인 등을 지원하는 테스트 프레임워크
- NTAF
- FitNesse의 장점인 협업과 STAF의 장점인 재사용 및 확장성을 통합한 NHN(Naver)의 테스트 자동화 프레임워크
- Selenium
- 다양한 브라우저 및 개발 언어를 지원하는 웹 애플리케이션 테스트 프레임워크
- watir
- Ruby를 사용하는 애플리케이션 테스트 프레임워크
테스트 드라이버 & 스텁
테스트 드라이버 (Driver)
- 테스트 대상 하위 모듈을 호출하고, 파라미터 전달, 모듈 테스트 수행 후의 결과 도출
- 상향식 테스트에 사용됨
테스트 스텁 (Stub)
- 제어 모듈이 호출하는 타 모듈의 기능을 단순히 수행하는 도구
- 하향식 테스트에 사용됨
이진 트리 순회
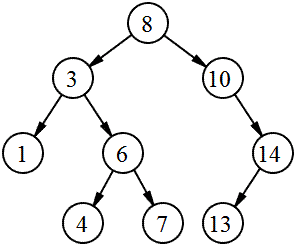
중위 순회 (in-order traversal)
왼 → me → 오
- 결과
1 → 3 → 4 → 6 → 7 → 8 → 10 → 14 → 13
- 왼쪽 자손, 자신, 오른쪽 자손 순서로 방문하는 순회 방법
- 이진 탐색 트리를 중위 순회하면 정렬된 결과를 얻을 수 있음
- 이를 트리 정렬(Tree sort)이라고 함
전위 순회 (pre-order traversal)
me → 왼 → 오
- 결과
8 → 3 → 1 → 6 → 4 → 7 → 10 → 14 → 13
- 자신, 왼쪽 자손, 오른쪽 자손 순서로 방문하는 순회 방법
후위 순회 (post-order traversal)
왼 → 오 → me
- 결과
1 → 4 → 7 → 6 → 3 → 13 → 14 → 10 → 8
- 왼쪽 자손, 오른쪽 자손, 자신 순서로 방문하는 순회 방법
레벨 순서 순회 (level-order traversal)
노드 레벨 순서대로
- 결과
8 → 3 → 10 → 1 → 6 → 14 → 4 → 7 → 13
- 너비 우선 순회(Breadth-First traversal)라고도 함
- 노드를 레벨 순서로 방문하는 순회 방법
- 위의 세 가지 방법은 스택을 활용하여 구현할 수 있는 반면 레벨 순서 순회는 큐를 활용해 구현할 수 있음
3과목 - 데이터베이스 구축
개체 무결성
- 모든 테이블이 기본키로 선택된 컬럼을 가져야함
참조 무결성
- 참조 관계의 두 테이블의 데이터가 항상 일관된 값을 갖도록 유지하는 것
도메인 무결성
- DB에서 무결성 규칙은 데이터 무결성을 지키기 위한 모든 제약사항 뜻함
무결성 규정
무결성 규정 요소
- 데이터가 만족해야 할 제약 조건과 참조할 때 사용하는 식별자 등을 포함할 수 있음
- 이는 데이터 무결성을 유지하기 위한 규칙이나 조건을 명시함
무결성 규정 대상
- 도메인 무결성, 키 무결성, 종속성 등이 데이터베이스 무결성 규정의 대상
- 도메인 무결성
- 특정 필드의 값이 정해진 도메인에 속해야 함을 보장
- 키 무결성
- 키 값의 유일성 및 존재성을 보장하는 것을 포함
릴레이션 무결성 규정
- 릴에이션을 조작하는 과정에서 의미적 관계를 명세한 것
- 데이터 간의 논리적인 관계와 연산 시 데이터의 무결성을 유지하는 규칙을 포함
데이터베이스 인덱스 (Index)
- 인덱스는 데이터를 빠르게 찾을 수 있는 수단으로, 테이블에 대한 조회 속도를 높여주는 자료 구조
- 인덱스는 자동으로 생성되지 않음
- 인덱스의 종류 중, 순서 인덱스(Ordered Index)는 B-Tree 알고리즘(오름차순/내림차순 지정 가능)을 활용
- ⚠️ 기본키에 대한 인덱스는 자동 생성
- ⚠️ 사용자가 데이터정의어를 사용해서 변경, 생성, 제거 가능
관계대수
- 관계대수는 관계형 데이터베이스에서 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어
- 릴레이션을 처리하기 위해 연산자와 연산 규칙을 제공하는 언어로 피연산자가 릴레이션이고, 결과도 릴레이션
- 질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시
- 관계대수에는 관계 데이터베이스에 적용하기 위해 특별히 개발한 순수 관계 연산자와 수학적 집합 이론에서 사용하는 일반 집합 연산자가 존재
순수 관계 연산자
- Select
- Project
- Join
- Division
일반 집합 연산자
- UNION (합집합)
- INTERSECTION (교집합)
- DIFFERENCE (차집합)
- CARTESIAN PRODUCT (교차곱)
함수적 종속
- 함수적 종속은 데이터들이 어떤 기준값에 의해 종속되는 것을 의미
- 예시
- <수강> 릴레이션이 (학번, 이름, 과목명)
학번이 결정되면과목명에 상관없이학번에는 항상 같은이름이 대응학번에 따라이름이 결정될 때,이름을학번에 함수 종속적이라고 함학번 → 이름과 같이 씀
C의 연산자
1. 관계 연산자
- 두 수의 관계를 비교하여 참(
true) 또는 거짓(false)을 결과로 얻는 연산자 - 거짓은
0, 참은1로 사용되지만,0이외의 모든 숫자도 참으로 간주됨
| 연산자 | 의미 |
|---|---|
== | 같음 |
!= | 같지 않음 |
> | 큼 (左) |
< | 작음 (左) |
>= | 크거나(左) 같음 |
<= | 작거나(左) 같음 |
2. 비트 연산자
- 비트 연산자는 비트별(0, 1)로 연산하여 결과를 얻는 연산자
| 연산자 | 의미 | 비고 |
|---|---|---|
& | and | 모든 비트가 1일때만 1 |
^ | xor | 모든 비트가 같으면 0, 하나라도 다르면 1 |
| | or | 모든 비트 중 한 비트라도 1이면 1 |
~ | not | 각 비트의 부정 (0 → 1 / 1 → 0) |
<< | 왼쪽 시프트 | 비트를 왼쪽으로 이동 |
>> | 오른쪽 시프트 | 비트를 오른쪽으로 이동 |
3. 논리 연산자
| 연산자 | 의미 | 비고 |
|---|---|---|
! | not | 부정 |
&& | and | 모두 참이면 true |
|| | or | 하나라도 참이면 true |
4. 대입 연산자
- 연산 후 결과를 대입하는 연산식을 간략하게 입력할 수 있도록 대입 연산자를 제공
- 산술, 관계, 비트, 논리 연산제에 모두 적용 가능
| 연산자 | 예시 | 의미 |
|---|---|---|
+= | a += 1 | a = a + 1 |
-= | a -= 1 | a = a - 1 |
*= | a *= 1 | a = a * 1 |
/= | a /= 1 | a = a / 1 |
%= | a %= 1 | a = a % 1 |
<<= | a «= 1 | a = a « 1 |
>>= | a »= 1 | a = a » 1 |
5. 조건 연산자
- 조건 연산자는 조건에 따라 서로 다른 수식을 수행
- 형식
조건 ? 수식1(true) : 수식2(false)조건의 수식이 참이면수식1을, 거짓이면수식2을 실행
6. 연산자의 우선순위
- 단항 연산자 (
!,~,++,--,sizeof) - 이항 연산자
- 산술 연산자 (
*,/,%,+,-) - 시프트 연산자 (
<<,>>) - 관계 연산자 (
<,<=,=>,>) - 비트 연산자 (
==,!=) - 논리 연산자 (
&,^,|)
- 산술 연산자 (
- 조건 연산자 (
a ? true : false) - 대입 연산자 (
=,+=,-=,*=,%=,<<=,>>=) - 순서 연산자 (
,)
4과목 - 프로그래밍 언어 활용
세그멘테이션 (Segmentation)
정의
- 프로세스를 논리적 내용일 기반으로 나눠 메모리에 배치하는 것을 말함
- 세그먼트의 집합으로, 각 세그먼트의 크기는 일반적으로 같지 않음
- 프로세스를
code,data,stack으로 나누는 것 역시 세그멘테이션의 모습- 각각 내부에서 더 작은 세그먼트로 나누는 것도 가능
세그먼트 주소 변환
| No. | Base | Limit |
|---|---|---|
| 0 | 1400 | 1000 |
| 1 | 6300 | 400 |
| 2 | 4300 | 400 |
| 3 | 3200 | 1100 |
| 4 | 4700 | 1000 |
- 논리주소 (2, 100) 계산하기 ⭕️
2번에 해당하는 열의Base값(4300)에100을 더함- 물리주소 =
4400번지
- 논리주소 (1,500) 계산하기 ❌
1번에 해당하는 열의Base값(6300)에500을 더함- ⚠️
Limit가400이기 때문에500값을 더할 수 없음 - 인터럽트로 인해 프로세스 강제 종료 (범위 벗어남)
5과목 - 정보시스템 구축관리
공개키(비대칭키) 암호화
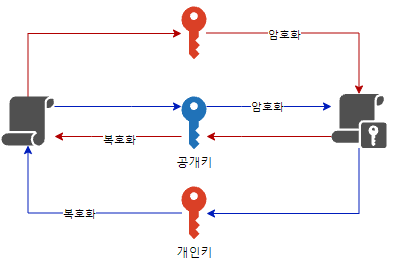
- 특징
- 복호화할 때의 키를 서로 다른 키로 사용하는 암호화 알고리즘
- 외부에 절대 노출되어서는 안되는 개인키(Private Key)와 공개적으로 개방되어 있는 공개키(Public Key)가 쌍으로 이루어진 형태
- 장점
- 키 분배 및 키 관리가 용이 (관리할 키 개수가 적음)
- 기밀성, 무결성을 지원
- 부인 방지1 기능을 제공
- 암호학적 문제 해결 가능
- 단점
- 상대적으로 키의 길이가 긺
- 연산 속도가 느림
- 종류
- RSA
- 디피-헬만 (Diffie-Hellman)
- 타원곡선암호 (Elliptic Curve Cryptosystem, ECC)
- 전자서명 (digital signature)
부인 방지: 송신자나 수신자가 메세지를 주고받은 사실을 부인하지 못하도록 방지하는 것 ↩︎
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.