[Data Structure] LinkedList (2) - 단일 연결리스트 구현 (Java)
Computer Science / Data Structure
Java의 자료 구조 중 하나인 LinkedList의 단일 연결리스트를 Java로 직접 구현

단일 연결리스트 자료 구조
단일 연결리스트(Singly LinkedList) 특징은 아래와 같이 요약할 수 있다.
- 노드(객체)를 연결하여 리스트처럼 만든 컬렉션이다.
- 배열이 아니다.
- 데이터의 중간 삽입/삭제가 빈번할 경우에 빠른 성능을 보장한다.
- 하지만, 임의의 요소에 대한 접근 성능이 좋지 않다.
- 특히 단일 연결리스트는 단방향 연결리스트이기 때문에 만일 리스트의 끝 요소를 탐색하려면, 처음(Head)부터 끝까지 순회하며 탐색해야 하기 떄문에 굉장히 효율이 떨어진다.
- 이를 개선한 것이 이중 연결리스트(Doubly LinkedList)이다.
- 데이터의 저장 순서가 유지되고 중복을 허용한다.


LinkedList에 대한 추가적인 설명에 대해서는 #LinkedList (1) - LinkedList 구조 게시글을 참고
단일 연결리스트 구현
단일 연결리스트의 경우, 자료 구조의 한계로 인해 탐색 성능이 좋지 못하기 때문에 현업에서는 잘 쓰이지 않는다고 한다.
실제 Java의 LinkedList 클래스 내부도 이중 연결리스트로 구현되어 있다.
하지만 해당 게시글에서는 이중 연결리스트의 작동 원리를 알기 위해 선수 지식으로 단일 연결리스트의 작동 원리부터 이해하기 위해 간단하게 add, remove 그리고 get, set 기능 정도로만 구현 예제를 작성할 예정이다.
클래스 필드 & 생성자 정의하기
1
2
3
4
5
6
7
8
9
10
11
12
public class MySinglyLinkedList<E> {
private Node<E> head; // 노드의 첫 부분을 가리키는 포인트
private Node<E> tail; // 노드의 마지막 부분을 가리키는 포인트
private int size; // 요소 개수
public MySinglyLinkedList() {
this.head = null;
this.tail = null;
this.size = 0;
}
}
head- 리스트의 가장 첫 노드를 가리키는 포인트로 이용될 변수
tail- 리스트의 가장 마지막 노드를 가리키는 포인트로 이용될 변수
size- 리스트에 있는 요소의 개수 (연결된 노드의 개수)
head와 tail 개념이 필요한 이유
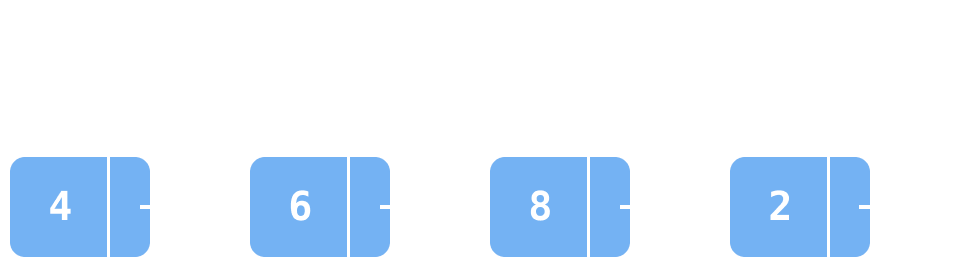
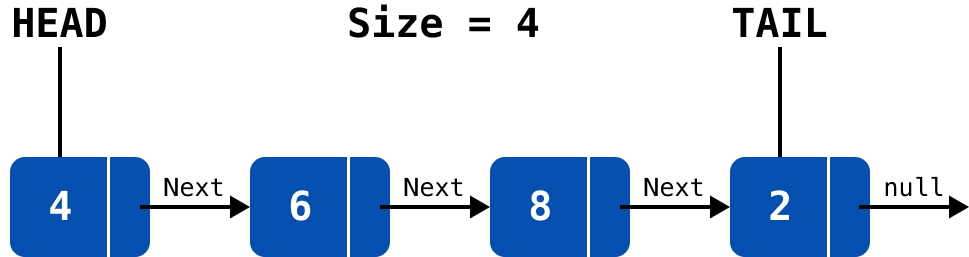
그냥 노드만 next로 서로 참조하여 연결하면 될 것을, 굳이 head와 tail이라는 개념이 필요한 이유는 가장 처음 요소와 가장 마지막 요소에 대한 링크를 표현하기 위함이다.
하나의 노드는 다음 노드 정보만 가지고 있기 때문에, 가장 첫 번째와 마지막 노드를 참조하고 있는 포인트를 만들 필요가 있고, 그것이 head이며 마지막 노드는 tail이다.
또한 뒤에서 나올 addLast() 메서드 같은 경우에는 요소를 맨 마지막에 추가할 때, tail이 없다면, add할 때마다 맨 마지막 요소가 어디까지인지를 알 길이 없기 때문에 항상 노드들을 처음부터 순회해야 할 수도 있다.
노드 클래스 정의하기
LinkedList의 경우, ArrayList와 가장 큰 차이점이라고 한다면 바로 “노드(Node)”라는 저장소를 이용하여 연결한다는 점이다.
쉽게 생각해서 노드는 그냥 객체이다.


위와 같이 이 클래스에는 자료를 저장할 Data라는 필드와 다음 연결 요소의 주소를 저장하는 Next라는 필드를 가지고 있을 뿐이다.
그리고 이 노드 객체들이 서로 연결된 형태가 바로 LinkedList인 것이다.
이전에 게시한 #ArrayList (2) - ArrayList 구현 (Java)의 ArrayList 구현의 경우, 오브젝트 배열(Object[])을 사용하여 데이터를 담아두었다면, LinkedList는 여러 노드 객체들을 내부적인 처리로 체인(Chain)처럼 연결한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class MySinglyLinkedList<E> {
// ...
// inner static class
private static class Node<E> {
private E item; // Node에 담을 데이터
private Node<E> next; // 다음 Node 객체를 가르키는 레퍼런스
// 생성자
Node(E item, Node<E> next) {
this.item = item;
this.next = next;
}
}
}
위의 코드에서 눈여겨 봐야할 점은 세 가지이다.
- 왜 클래스 안에다가 클래스를 선언하였는가?
- 왜
private접근 지시자인가? - 왜
static이 붙었는가?
물론, Node 클래스를 MySinglyLinkedList 클래스 밖에서 선언해도 문제는 없다.
다만, Node 클래스는 오로지 MySinglyLinkedList 클래스에서만 이용되며, 다른 클래스에서는 전혀 사용되지 않는다.
이때 내부 클래스로 선언해주면 여러가지 장점을 얻게 되는데, 내부 클래스의 장점으로는 아래와 같다.
- 클래스를 논리적으로 그룹화
- 클래스가 여러 클래스와 관계를 맺지 않고 하나의 특정 클래스와만 관계를 맺는다면, 내부 클래스와 외부 클래스를 함께 관리하는 것이 가능해져서 유지보수 측면에서나 코드 이해성 면에서 편리해진다.
- 또한 내부 클래스로 인해 새로운 클래스를 생성하지 않아되므로, 패키지를 간소화할 수 있다.
- 더욱 타이트한 캡슐화의 적용
- 내부 클래스에
private제어자를 적용해 줌으로써, 캡슐화를 통해 클래스를 내부로 숨길 수 있다.
- 즉, 캡슐화를 통해 외부에서의 접근은 차단하며 내부 클래스에서 외부 클래스의 멤버들을 제약 없이 쉽게 접근할 수 있어서 구조적인 프로그래밍이 가능해진다.
- 그리고 클래스 구조를 숨김으로써 코드의 복잡성도 줄일 수 있다.
- 내부 클래스에
- 가독성이 좋고 유지 관리가 쉬운 코드
- 하나의 클래스를 다른 클래스 내부 클래스로 선언하면 두 클래스 멤버들 간에 서로 자유로이 접근이 가능하며, 외부에는 불필요한 클래스를 감춰서 클래스 간의 연관 관계를 따지는 것과 같은 코드의 복잡성을 줄일 수 있다.
- 간단하게 말하면, 어차피 A 클래스 안에서만 사용하기 위한 클래스이기 때문에 괜히 연관 관계 생각 없이 내부에 선언해 직관적으로 사용하자는 취지인 것이다.
그리고 private 접근 제어자의 경우, 객체가 외부로 노출되면 보안 상의 문제가 발생할 수 있기 때문에 오로지 MySinglyLinkedList 메소드로만 제어가 가능하도록 하기 위해 설정되었다.
마지막으로 내부 클래스를 static으로 선언한 이유는 메모리 누수(Memory Leak)1 이슈 때문이다.
search 구현하기
add와 remove를 구현하기에 앞서, ㅉ따로 내부 메소드 용으로 search()를 구현하고자 한다.
add와 remove를 구현하기 위해서는 우선 추가/삭제할 요소 탐색이 우선이 되기 때문에, 반복적으로 재사용되어 별도의 메소드로 구현한다.
LinkedList의 검색의 경우, 인덱스가 없기 때문에 랜덤 엑세스를 할 수 없다.
따라서 $n$개의 노드를 가지고 있는 노드를 검색할 때 시간 복잡도는 $O(n)$이 된다.
1
2
3
4
5
6
7
8
9
10
private Node<E> search(int index) {
// head(처음 위치)에서부터 차례로 index까지 검색
Node<E> n = head;
for (int i = 0; i < index; i++) {
n = n.next; // next 필드의 값(다음 노드 주소)를 재대입하면서 순차적으로 요소를 탐색
}
return n;
}
이때, 반복문 범위를 index까지 탐색이 아닌 index 전까지만의 탐색(i < index)되어야 하는데, 그 이유는 노드의 next 필드 자체가 그 다음 노드를 가리키기 때문이다.
add 구현하기
Java의 LinkedList 클래스의 add의 종류를 보면 아래와 같이 4가지가 존재한다.
void addFirst(Object obj)- 첫 번째 위치에 요소 추가
void addLast(Object obj)- 마지막 위치에 요소 추가
boolean add(Object obj)- 마지막 위치에 요소 추가 (성공하면
true출력)
- 마지막 위치에 요소 추가 (성공하면
void add(int index, Object element)- 지정된 위치에 요소 추가
addFirst 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// add
public void addFirst(E value) {
// 1. 먼저 가장 앞의 요소를 가져옴
Node<E> first = head;
// 2. 새 노드 생성
// 이때 데이터와 next 포인트를 준다.
Node<E> newNode = new Node<>(value, first);
// 3. 요소가 추가되었으니 size를 늘린다.
size++;
// 4. 맨 앞에 요소가 추가되었으니 head를 업데이트한다.
head = newNode;
// 5. 만일 최초로 요소가 add 된 것이면, head와 tail이 가리키는 요소는 같게 된다.
if (first == null) {
tail = newNode;
}
}
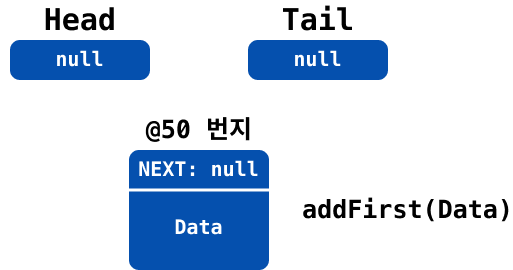
LinkedList에 요소가 첫 번째에 추가되는 과정을 이미지로 표현하자면 아래와 같다.
head의 값(@100번지 객체)을first변수에 백업

새 노드를 추가하면서 요소 값과
tmp값(@100)을 넣어 초기화 및 다음 요소로 연결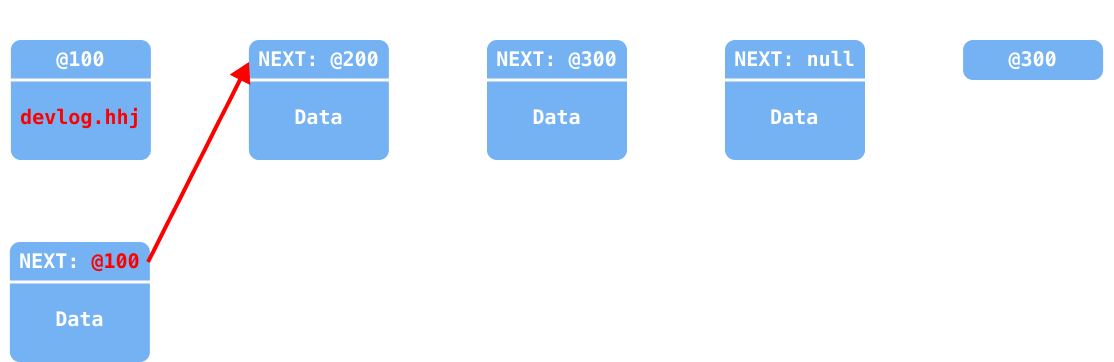
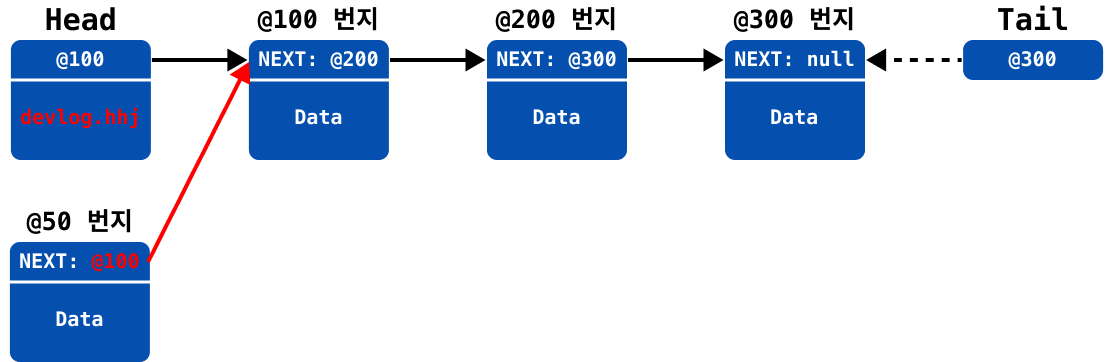
head가 새 노드를 바라보도록 업데이트 (@100→@105)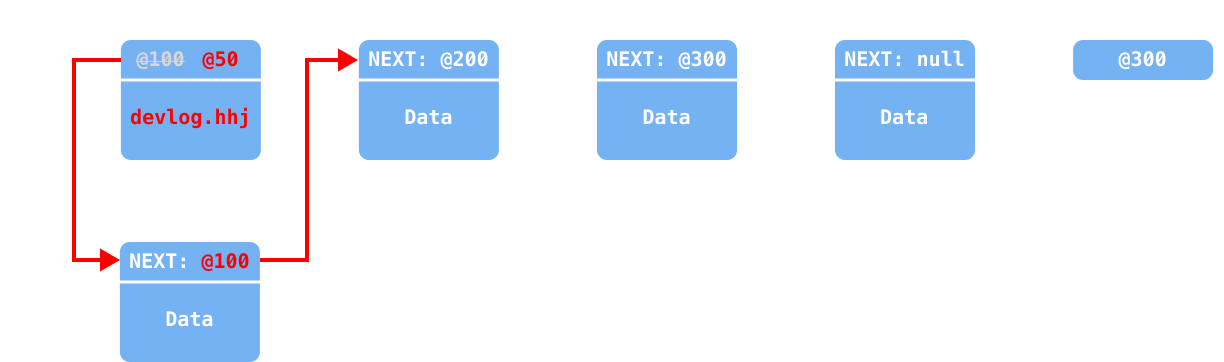
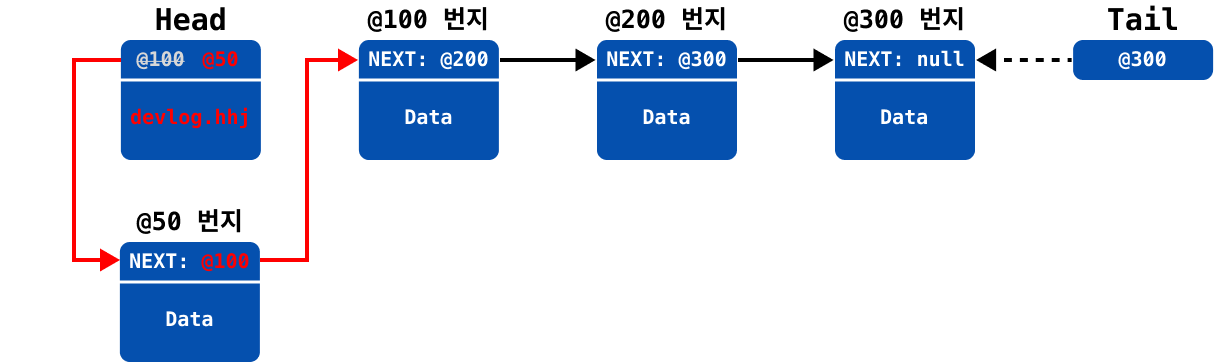
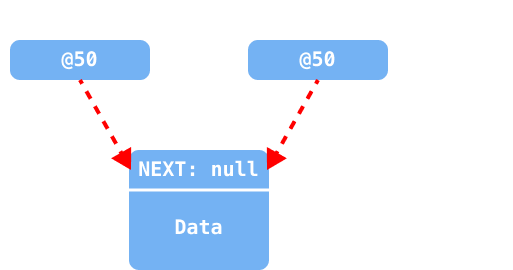
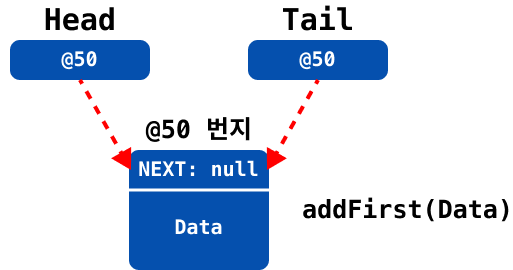
만약에 최초의 요소를 추가하는 것이라면, 아래와 같이 head와 tail이 하나의 객체를 바라보도록 설정해야 한다.
head가null일 경우
head와tail이 최초로 추가된 새 노드를 바라보도록 업데이트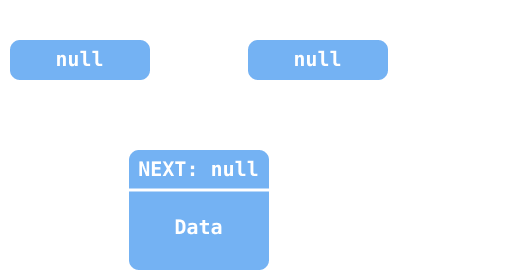
addLast 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public void addLast(E value) {
// 1. 먼저 가장 뒤의 요소를 가져옴
Node<E> last = tail;
// 2. 새 노드 생성
// 맨 마지막 요소 추가이기에 next는 null
Node<E> newNode = new Node<>(value, null);
// 3. 요소가 추가되었으니 size를 늘린다.
size++;
// 4. 맨 뒤에 요소가 추가되었으니 tail을 업데이트
tail = newNode;
if (last == null) {
// 5. 만일 최초로 요소가 add 된 것이면 head와 tail이 가리키는 요소는 같게 된다.
head = newNode;
} else {
// 6. 최초 추가가 아니라면 last 변수(추가되기 전 마지막이었던 요소)에서 추가된 새 노드를 가리키도록 업데이트
last.next = newNode;
}
}
LinkedList에 요소가 마지막에 추가되는 과정을 이미지로 표현하자면 아래와 같다.
last변수에 현재 마지막 요소(@300)를 백업

새 노드를 추가하고
tail을 업데이트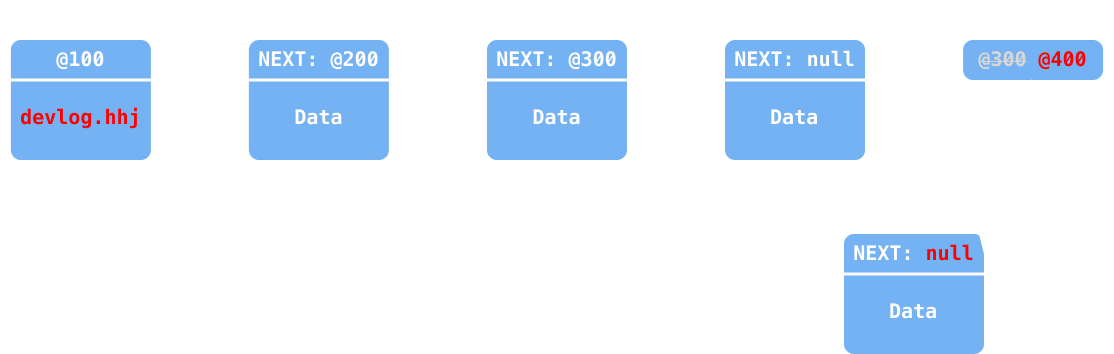
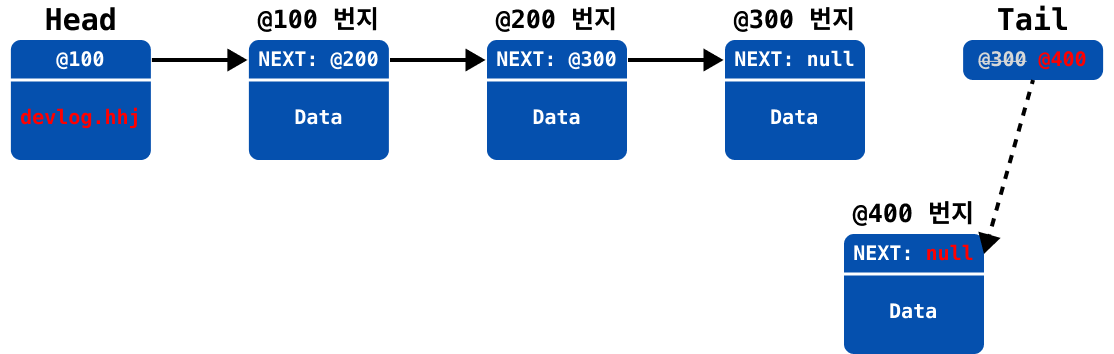
요소가 추가되기 이전의 요소(
last변수)에서next를 업데이트 (null→@400)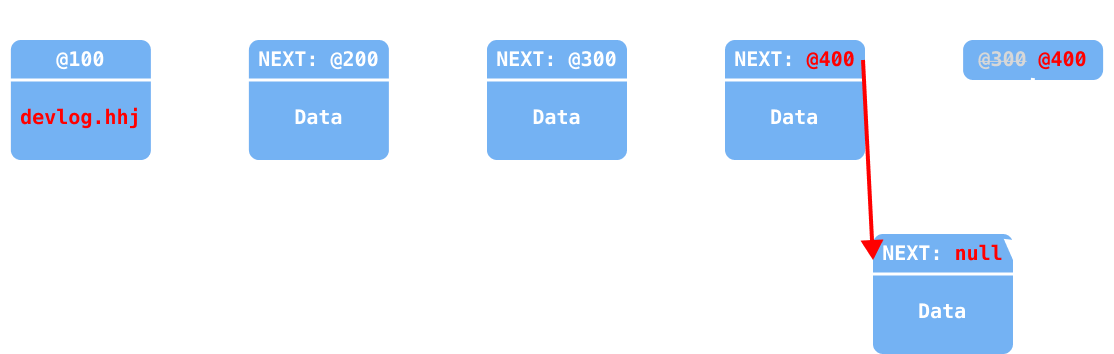
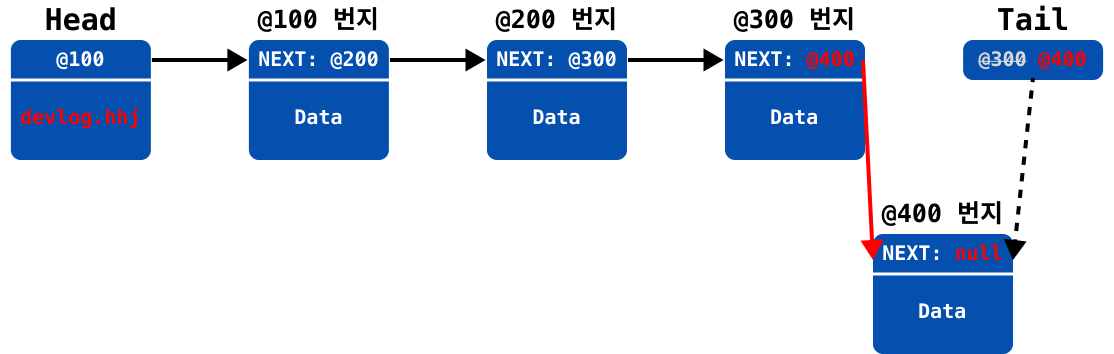
add 구현
add()의 동작은 addList()와 같으며, 실제로 LinkedList API를 보면 add 메소드를 호출하면 addLast()를 호출한다.
1
2
3
4
public boolean add(E value) {
addLast(value);
return true;
}
add 중간 삽입 구현
- 리스트 중간에 삽입하기 위해서는 가장 먼저 인덱스 범위를 체크해야 한다.
- 인덱스가 처음과 끝이면 위에서 구현한
addFirst,addLast를 재활용하면 된다. - 추가하려는 위치를 구하기 위해 위에서 구현한
search메서드를 이용한다. - 이전 노드(
prev_node)와 다음 노드(next_node) 참조 값을 변수에 백업하는 것이 포인트이다. prev_node의next는new_node에 연결,new_node는next_node에 연결시키도록 함으로써 삽입이 완료된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public void add(int index, E value) {
// 1. 인덱스가 0보다 작거나 size보다 같거나 클 경우 에러
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
// 2. 추가하려는 index가 0이면, addFirst 호출
if (index == 0) {
addFirst(value);
return;
}
// 3. 추가하려는 index가 size - 1과 같으면, addLast 호출
if (index == size) {
addLast(value);
return;
}
// 4. 추가하려는 위치의 이전 노드 얻기
Node<E> prev_node = search(index - 1);
// 5. 추가하려는 위치의 다음 노드 얻기
Node<E> next_node = prev_node.next;
// 6. 새 노드 생성 (바로 다음 노드와 연결)
Node<E> newNode = new Node<>(value, next_node);
// 7. size 증가
size++;
// 8. 이전 노드를 새 노드와 연결
prev_node.next = newNode;
}
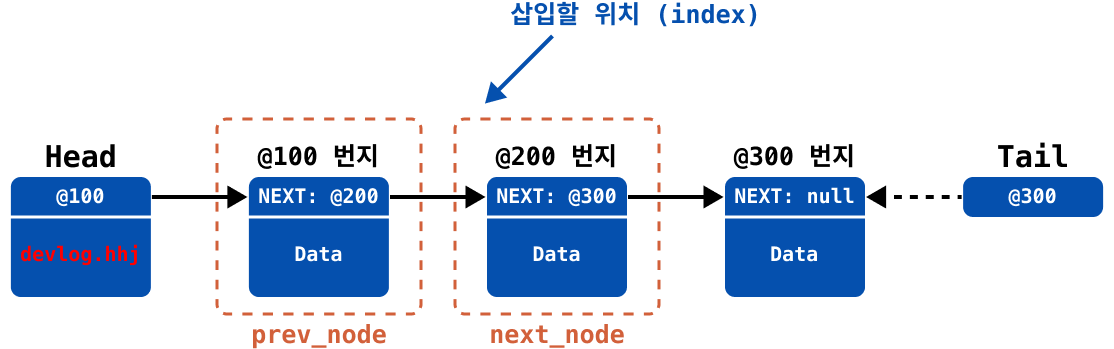
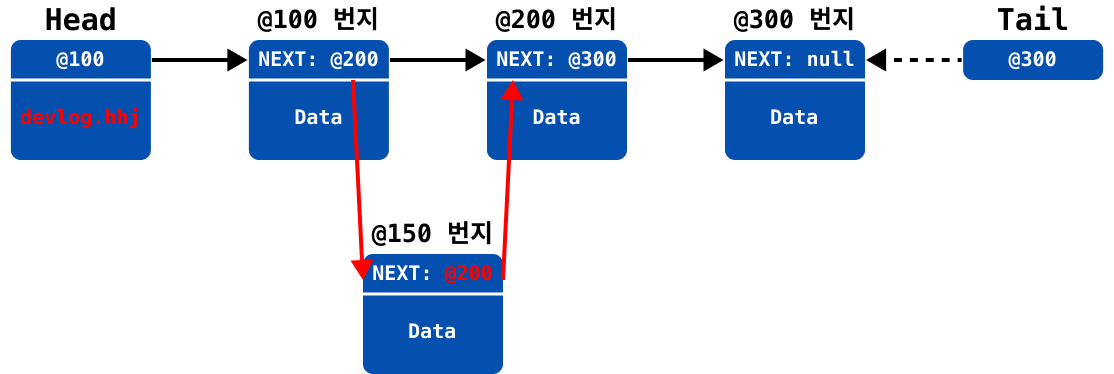
만약에 index가 1인 위치(@200 번지)에 노드를 삽입한다고 가정한다면, add 중간 삽입 과정은 아래와 같다.
추가하려는 위치의 이전 노드(
prev_node)와 다음 노드(next_node)를 임시 저장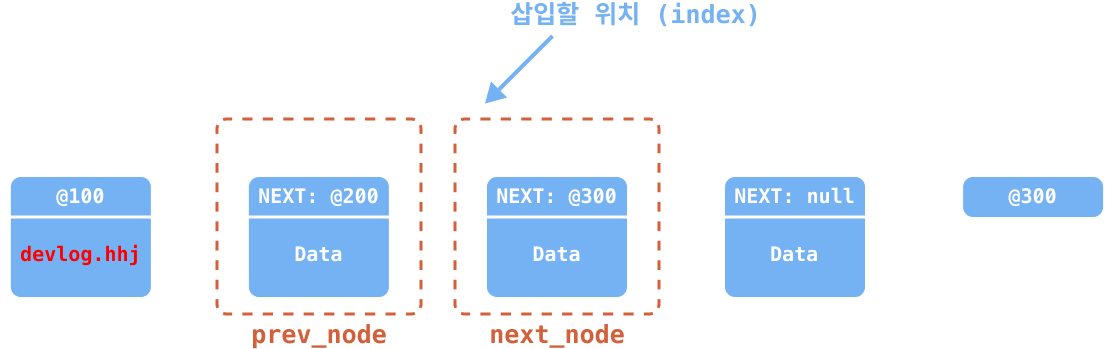
새 노드 생성 (생성하며 다음 노드에 연결)
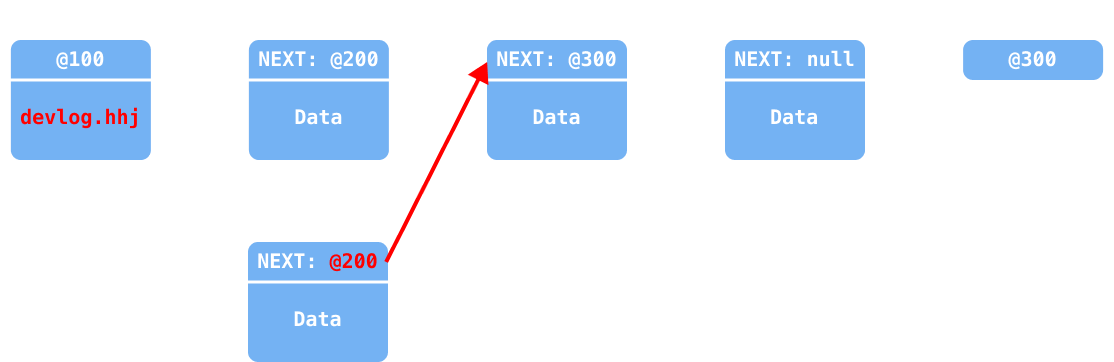
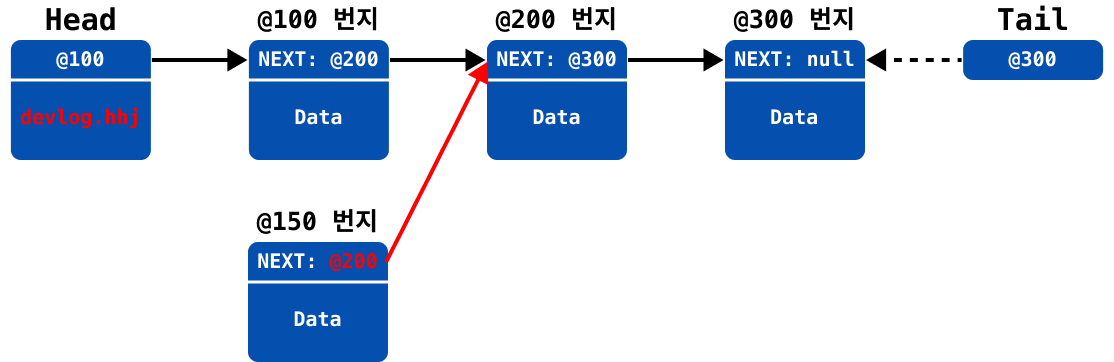
이전 노드의 참조를 추가된 새 노드에 연결 (
@200→@150)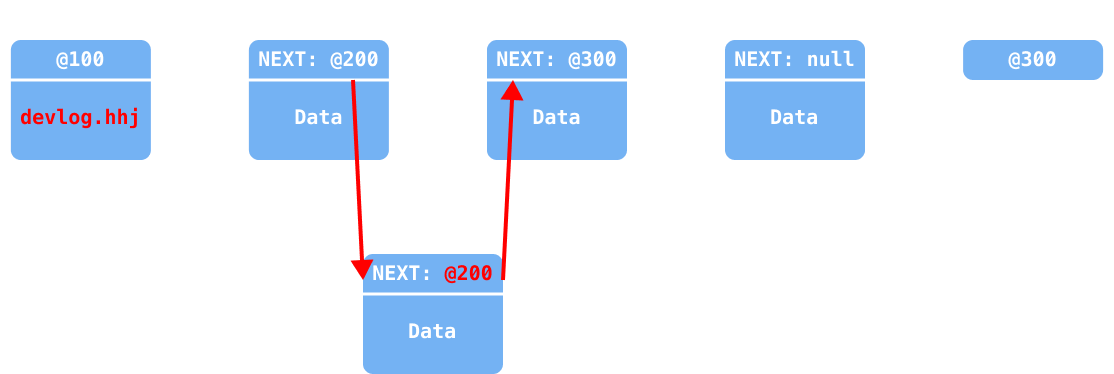
remove 구현하기
LinkedList의 remove 메서드에는 다음과 같이 총 5가지가 존재한다.
Object removeFirst()- 맨 앞 요소를 제거 (제거한 요소는 반환)
Object remove()- 맨 앞 요소를 제거
Object removeLast()- 맨 뒤 요소를 제거
Object remove(int index)index위치의 요소를 제거
boolean remove(Object value)- 요소 값이 일치하는 위치의 요소를 제거
- 중복 요소 값이 있는 경우, 맨 앞의 요소를 제거
remove 작동 원리는 add 메커니즘의 반대로 생각해서 구현해주면 된다.
removeFirst 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public E removeFirst() {
// 1. 만약 삭제할 요소가 아무 것도 없다면, 에러
if (head == null) {
throw new IndexOutOfBoundsException();
}
// 2. 삭제될 첫 번째 요소의 데이터를 백업
E returnValue = head.item;
// 3. 두 번째 노드를 임시 저장
Node<E> first = head.next;
// 4. 첫 번째 노드의 내부 요소를 모두 삭제
head.next = null;
head.item = null;
// 5. head가 다음 노드를 가리키도록 업데이트
head = first;
// 6. 요소가 삭제되었으니, 크기 감소
size--;
// 7. 만일 리스트의 유일한 값을 삭제해서 빈 리스트가 될 경우, tail도 null처리
if (head == null) {
tail = null;
}
// 8. 마지막으로 삭제된 요소를 반환
return returnValue;
}
- 삭제 후 반환할 첫 번째 요소 데이터를 백업한다.
첫 번째 요소가 삭제되면, 두 번째 요소가 첫 번째가 되기 때문에 두 번째 요소를 변수
first에 저장해서 나중에 다루도록 한다.
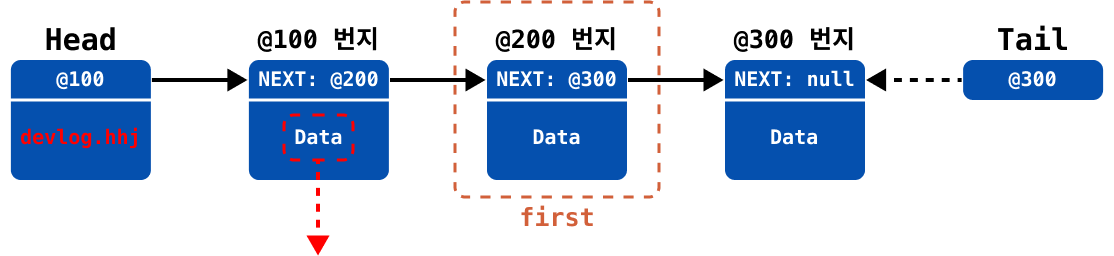
첫 번째 노드의 모든 데이터를
null로 처리한다.

head의 포인트를first변수에 저장해두었던 두 번째 노드(@200)으로 업데이트한다.아무 것도 연결되지 않아 고아가 되어버린 노드는 나중에 GC2가 수거해 간다.
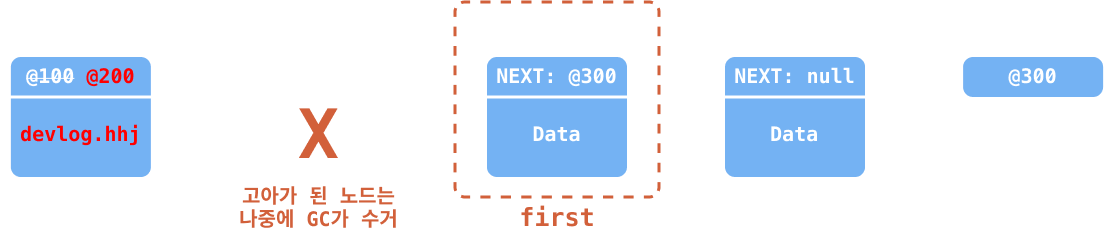

추가적으로 만일 삭제할 요소가 리스트의 유일한 요소라면, 삭제 시에 빈 리스트가 되기 때문에
head와tail을null이 되도록 업데이트 해준다.





remove 구현
LinkedList의 기본 remove() 동작은 add()와 달리 첫 번째 요소를 처리한다.
1
2
3
public E remove() {
return removeFirst();
}
index로 remove 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public E remove(int index) {
// 1. index가 0보다 작거나, size보다 크거나 같은 경우 에러
// (size와 같다면, 빈 공간을 가리키기 때문)
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
// 2. index가 0이면 removeFirst 메서드를 실행하고 return
if (index == 0) {
return removeFirst();
}
// 3. 삭제할 위치의 이전 노드를 저장
Node<E> prev_node = search(index - 1);
// 4. 삭제할 위치의 노드를 저장
Node<E> del_node = prev_node.next;
// 5. 삭제할 위치의 다음 노드를 저장
Node<E> next_node = del_node.next;
// 6. 삭제될 첫 번째 요소의 데이터를 백업
E returnValue = del_node.item;
// 7. 삭제 노드의 내부 요소를 모두 삭제
del_node.item = null;
del_node.next = null;
// 8. 요소가 삭제되었으니 크기 감소
size--;
// 9. 이전 노드가 다음 노드를 가리키도록 업데이트
prev_node.next = next_node;
// 10. 마지막으로 삭제된 요소를 반환
return returnValue;
}
- 만약에 index 1의 요소를 삭제한다고 하면, 먼저 삭제할 위치를 탐색한다.
search메서드에서 반환한 노드를 이용하여, 삭제하려는 위치의 이전 노드(prev_node)와 삭제 노드(del_node), 그리고 다음 노드(next_node) 참조 값을 변수 3개에 저장한다.반환할 데이터를 백업해둔다.
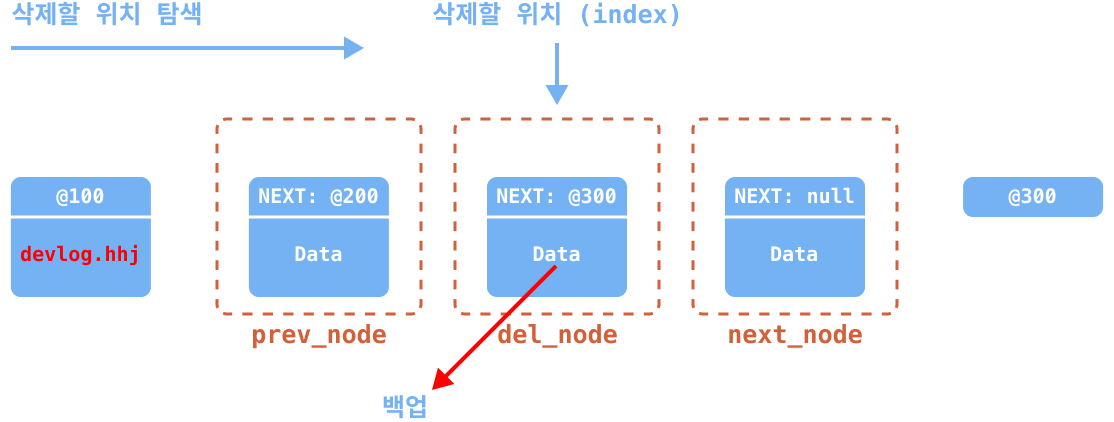
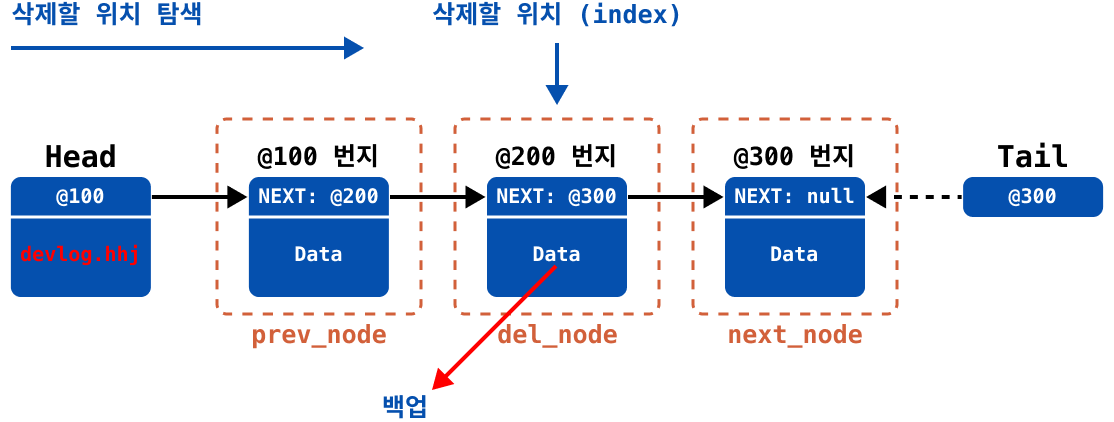
del_node의 데이터를 모두 삭제한다.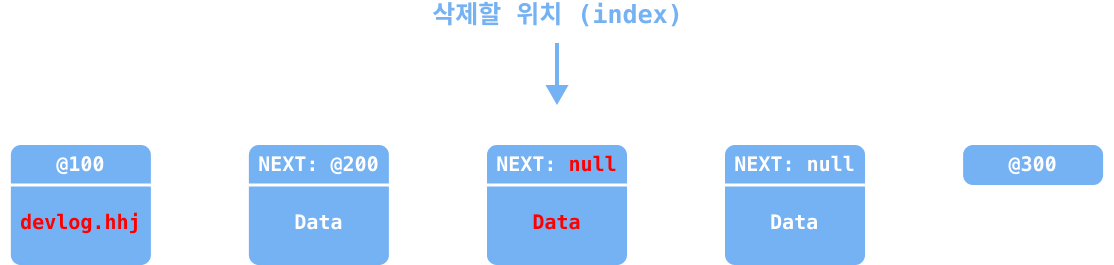
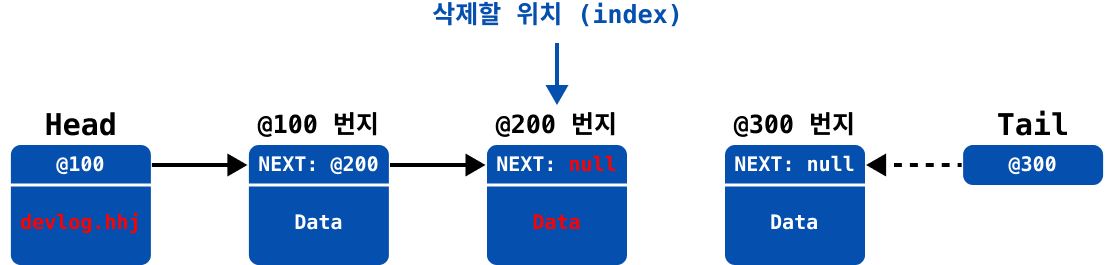
prev_node의next값을next_node로 재설정한다.

값으로 remove 구현
값으로 요소를 remove하는 로직은 약간 복잡하다.
왜냐하면, search() 메서드를 사용할 수 없기 떄문에 직접 순회하는 전략으로 구성해야 하기 때문이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import java.util.Objects;
public boolean remove(Object value) {
// 1. 만약, 삭제할 요소가 아무 것도 없다면, 에러
if (head == null) {
throw new RuntimeException();
}
// 2. 이전 노드, 삭제 노드, 다음 노드를 저장할 변수 선언
Node<E> prev_node = null;
Node<E> del_node = null;
Node<E> next_node = null;
// 3. 루프 변수 선언
Node<E> i = head;
// 4. 노드의 next를 순회하면서 해당 값을 찾는다.
while (i != null) {
if (Objects.equals(value, i.item)) {
// 노드의 값과 매개 변수 값이 같으면 삭제 노드에 요소를 대입하고 break
del_node = i;
break;
}
// Singly LinkedList에는 prev 정보가 없기 때문에, 이전 노드에도 요소를 일일니 대입해야 한다.
prev_node = i;
i = i.next;
}
// 5. 만약에 찾는 요소가 없다면 false
if (del_node == null) {
return false;
}
// 6. 만약에 삭제하려는 노드가 head라면, 첫 번째 요소를 삭제하는 것이니 removeFirst()를 사용
if (del_node == head) {
removeFirst();
return true;
}
// 7. 다음 노드에 삭제 노드 next의 요소를 대입
next_node = del_node.next;
// 8. 삭제 요소 데이터 모두 제거
del_node.item = null;
del_node.next = null;
// 9. 요소가 삭제되었으니, 크기 감소
size--;
// 10. 이전 노드가 다음 노드를 참조하도록 업데이트
prev_node.next = next_node;
return true;
}
removeLast 구현
위에서 구현한 remove(int index) 메서드를 재활용하여 구현할 수 있다.
따라서 탐색 시간이 소요되기 때문에 removeFirst()보다는 $O(n)$의 시간이 걸리게 된다.
addLast()와 같이 tail을 이용해서 상수 시간 안으로 처리되도록 구현할 법도 하지만, 단일 연결리스트는 노드 prev 개념이 없기 때문에 삭제될 노드의 이전 요소를 참조할 방법이 없기 떄문에, 결국은 처음부터 끝까지 순회해야 한다는 단점이 존재한다.
1
2
3
public E removeLast() {
return remove(size - 1);
}
get 구현하기
위에서 구현한 search 메서드로 노드를 검색하여 값을 반환하면 된다.
1
2
3
4
5
6
7
public E get(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
return search(index).item;
}
set 구현하기
1
2
3
4
5
6
7
8
9
10
11
12
public void set(int index, E value) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
// 1. search 메서드를 이용해 교체할 노드를 얻는다.
Node<E> replace_node = search(index);
// 2. 교체할 노드의 요소를 변경한다.
replace_node.item = null;
replace_node.item = value;
}
toString 구현하기
마지막으로 연결리스트의 요소들을 출력하기 위해 Object 클래스의 toString() 메소드를 오버라이딩하도록 한다.
연결리스트 출력은 어렵게 생각할 필요 없이, 배열을 만들고, 각 배열 index마다 리스트의 노드 요소 값을 대입해서 복사를 한 뒤, 문자열로 만들어 반환해주면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import java.util.Arrays;
@Override
public String toString() {
// 1. 만약에 head가 null일 경우, 빈 배열
if (head == null) {
return "[]";
}
// 2. 현재 size만큼 배열 생성
Object[] array = new Object[size];
// 3. 노드 next를 순회하면서 배열에 노드 값을 저장
int index = 0;
Node<E> n = head;
while (n != null) {
array[index] = (E) n.item;
index++;
n = n.next;
}
// 3. 배열을 string화하여 반환
return Arrays.toString(array);
}
또는 아래의 코드와 같이 직접 문자열 더하기 연산으로도 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Override
public String toString() {
// 1. 만약에 head가 null일 경우, 빈 배열
if (head == null) {
return "[]";
}
Node<E> n = head;
String result = "[";
while (n.next != null) {
result += n.item + ", ";
n = n.next;
}
// n이 마지막일 경우, n.next가 null이기 때문에 루프문을 빠져나오게 되서 마지막 노드 삽입 처리를 해줘야 한다.
result += n.item + "]";
return result;
}
단일 연결리스트 구현 전체 코드
MySinglyLinkedList
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
package linkedlist;
import java.util.Arrays;
import java.util.Objects;
public class MySinglyLinkedList<E> {
private Node<E> head; // 노드의 첫 부분을 가리키는 포인트
private Node<E> tail; // 노드의 마지막 부분을 가리키는 포인트
private int size; // 요소 갯수
public MySinglyLinkedList() {
this.head = null;
this.tail = null;
this.size = 0;
}
// inner static class
private static class Node<E> {
private E item; // Node에 담을 데이터
private Node<E> next; // 다음 Node 객체를 가르키는 레퍼런스
// 생성자
Node(E item, Node<E> next) {
this.item = item;
this.next = next;
}
}
// search
private Node<E> search(int index) {
// head(처음 위치)에서부터 차례로 index까지 검색
Node<E> n = head;
for (int i = 0; i < index; i++) {
n = n.next; // next 필드의 값(다음 노드 주소)를 재대입하면서 순차적으로 요소를 탐색
}
return n;
}
// ---------------------------- add ----------------------------
public void addFirst(E value) {
// 1. 먼저 가장 앞의 요소를 가져옴
Node<E> first = head;
// 2. 새 노드 생성
// 이때 데이터와 next 포인트를 준다.
Node<E> newNode = new Node<>(value, first);
// 3. 요소가 추가되었으니 size를 늘린다.
size++;
// 4. 맨 앞에 요소가 추가되었으니 head를 업데이트한다.
head = newNode;
// 5. 만일 최초로 요소가 add 된 것이면, head와 tail이 가리키는 요소는 같게 된다.
if (first == null) {
tail = newNode;
}
}
public void addLast(E value) {
// 1. 먼저 가장 뒤의 요소를 가져옴
Node<E> last = tail;
// 2. 새 노드 생성
// 맨 마지막 요소 추가이기에 next는 null
Node<E> newNode = new Node<>(value, null);
// 3. 요소가 추가되었으니 size를 늘린다.
size++;
// 4. 맨 뒤에 요소가 추가되었으니 tail을 업데이트
tail = newNode;
if (last == null) {
// 5. 만일 최초로 요소가 add 된 것이면 head와 tail이 가리키는 요소는 같게 된다.
head = newNode;
} else {
// 6. 최초 추가가 아니라면 last 변수(추가되기 전 마지막이었던 요소)에서 추가된 새 노드를 가리키도록 업데이트
last.next = newNode;
}
}
public boolean add(E value) {
addLast(value);
return true;
}
public void add(int index, E value) {
// 1. 인덱스가 0보다 작거나 size보다 같거나 클 경우 에러
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
// 2. 추가하려는 index가 0이면, addFirst 호출
if (index == 0) {
addFirst(value);
return;
}
// 3. 추가하려는 index가 size - 1과 같으면, addLast 호출
if (index == size) {
addLast(value);
return;
}
// 4. 추가하려는 위치의 이전 노드 얻기
Node<E> prev_node = search(index - 1);
// 5. 추가하려는 위치의 다음 노드 얻기
Node<E> next_node = prev_node.next;
// 6. 새 노드 생성 (바로 다음 노드와 연결)
Node<E> newNode = new Node<>(value, next_node);
// 7. size 증가
size++;
// 8. 이전 노드를 새 노드와 연결
prev_node.next = newNode;
}
// ---------------------------- remove ----------------------------
public E removeFirst() {
// 1. 만약 삭제할 요소가 아무 것도 없다면, 에러
if (head == null) {
throw new IndexOutOfBoundsException();
}
// 2. 삭제될 첫 번째 요소의 데이터를 백업
E returnValue = head.item;
// 3. 두 번째 노드를 임시 저장
Node<E> first = head.next;
// 4. 첫 번째 노드의 내부 요소를 모두 삭제
head.next = null;
head.item = null;
// 5. head가 다음 노드를 가리키도록 업데이트
head = first;
// 6. 요소가 삭제되었으니, 크기 감소
size--;
// 7. 만일 리스트의 유일한 값을 삭제해서 빈 리스트가 될 경우, tail도 null처리
if (head == null) {
tail = null;
}
// 8. 마지막으로 삭제된 요소를 반환
return returnValue;
}
public E remove() {
return removeFirst();
}
public E remove(int index) {
// 1. index가 0보다 작거나, size보다 크거나 같은 경우 에러
// (size와 같다면, 빈 공간을 가리키기 때문)
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
// 2. index가 0이면 removeFirst 메서드를 실행하고 return
if (index == 0) {
return removeFirst();
}
// 3. 삭제할 위치의 이전 노드를 저장
Node<E> prev_node = search(index - 1);
// 4. 삭제할 위치의 노드를 저장
Node<E> del_node = prev_node.next;
// 5. 삭제할 위치의 다음 노드를 저장
Node<E> next_node = del_node.next;
// 6. 삭제될 첫 번째 요소의 데이터를 백업
E returnValue = del_node.item;
// 7. 삭제 노드의 내부 요소를 모두 삭제
del_node.item = null;
del_node.next = null;
// 8. 요소가 삭제되었으니 크기 감소
size--;
// 9. 이전 노드가 다음 노드를 가리키도록 업데이트
prev_node.next = next_node;
// 10. 마지막으로 삭제된 요소를 반환
return returnValue;
}
public boolean remove(Object value) {
// 1. 만약, 삭제할 요소가 아무 것도 없다면, 에러
if (head == null) {
throw new RuntimeException();
}
// 2. 이전 노드, 삭제 노드, 다음 노드를 저장할 변수 선언
Node<E> prev_node = null;
Node<E> del_node = null;
Node<E> next_node = null;
// 3. 루프 변수 선언
Node<E> i = head;
// 4. 노드의 next를 순회하면서 해당 값을 찾는다.
while (i != null) {
if (Objects.equals(value, i.item)) {
// 노드의 값과 매개 변수 값이 같으면 삭제 노드에 요소를 대입하고 break
del_node = i;
break;
}
// Singly LinkedList에는 prev 정보가 없기 때문에, 이전 노드에도 요소를 일일니 대입해야 한다.
prev_node = i;
i = i.next;
}
// 5. 만약에 찾는 요소가 없다면 false
if (del_node == null) {
return false;
}
// 6. 만약에 삭제하려는 노드가 head라면, 첫 번째 요소를 삭제하는 것이니 removeFirst()를 사용
if (del_node == head) {
removeFirst();
return true;
}
// 7. 다음 노드에 삭제 노드 next의 요소를 대입
next_node = del_node.next;
// 8. 삭제 요소 데이터 모두 제거
del_node.item = null;
del_node.next = null;
// 9. 요소가 삭제되었으니, 크기 감소
size--;
// 10. 이전 노드가 다음 노드를 참조하도록 업데이트
prev_node.next = next_node;
return true;
}
public E removeLast() {
return remove(size - 1);
}
public E get(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
return search(index).item;
}
public void set(int index, E value) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
// 1. search 메서드를 이용해 교체할 노드를 얻는다.
Node<E> replace_node = search(index);
// 2. 교체할 노드의 요소를 변경한다.
replace_node.item = null;
replace_node.item = value;
}
@Override
public String toString() {
// 1. 만약에 head가 null일 경우, 빈 배열
if (head == null) {
return "[]";
}
// 2. 현재 size만큼 배열 생성
Object[] array = new Object[size];
// 3. 노드 next를 순회하면서 배열에 노드 값을 저장
int index = 0;
Node<E> n = head;
while (n != null) {
array[index] = (E) n.item;
index++;
n = n.next;
}
// 3. 배열을 string화하여 반환
return Arrays.toString(array);
}
// @Override
// public String toString() {
// // 1. 만약에 head가 null일 경우, 빈 배열
// if (head == null) {
// return "[]";
// }
// Node<E> n = head;
// String result = "[";
// while (n.next != null) {
// result += n.item + ", ";
// n = n.next;
// }
// // n이 마지막일 경우, n.next가 null이기 때문에 루프문을 빠져나오게 되서 마지막 노드 삽입 처리를 해줘야 한다.
// result += n.item + "]";
// return result;
// }
}
실행 결과
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
package linkedlist;
public class Client {
@SuppressWarnings("removal")
public static void main(String[] args) {
MySinglyLinkedList<Number> l = new MySinglyLinkedList<>();
l.add(3);
l.add(6);
l.add(4);
l.add(3);
l.add(8);
l.add(10);
l.add(11);
System.out.println(l);
// [3, 6, 4, 3, 8, 10, 11]
l.add(6, 100);
l.add(0, 101);
l.add(1, 102);
System.out.println(l);
// [101, 102, 3, 6, 4, 3, 8, 10, 100, 11]
l.removeFirst();
l.removeFirst();
l.remove(1);
System.out.println(l);
// [3, 4, 3, 8, 10, 100, 11]
// @SuppressWarnings("removal") 추가 필요
l.remove(new Integer(3));
l.remove(new Integer(3));
System.out.println(l);
// [4, 8, 10, 100, 11]
System.out.println(l.get(1));
// 8
l.set(4, 999);
System.out.println(l);
// [4, 8, 10, 100, 999]
}
}
참고 사이트
자바에서의 메모리 누수(Memory Leak)이란, 더 이상 사용되지 않는 객체들이 가비지 컬렉터에 의해 회수되지 않고 계속 누적되는 현상을 말하며, Old 영역에 계속 누적된 개게로 인해 Major GC가 빈번하게 발생하게 되면서, 프로그램 응답속도가 늦어지면서 성능 저하를 일으키며 결국
OutOfMemory Error로 프로그램이 종료된다. ↩︎가비지 컬렉션(GC, Garbage Collection)이란, 자바 가상 머신(JVM)에 의해 구동되는 자바 프로그램은 메모리 관리를 개발자가 직접 명시적으로 수행하지 않고 자동 메모리 관리 기능을 지원하는데, 가비지 컬렉션은 자바의 메모리 관리 방법 중의 하나로, 자바 가상 머신의 Heap 영역에서 동적으로 할당했던 메모리 중에 필요 없게 된 메모리 객체를 모아 주기적으로 제거하는 프로세스를 말한다. ↩︎