[Data Structure] Stack VS Queue
Computer Science / Data Structure
자료 구조인 Stack과 Queue의 각 특징과 장단점, 활용 정리
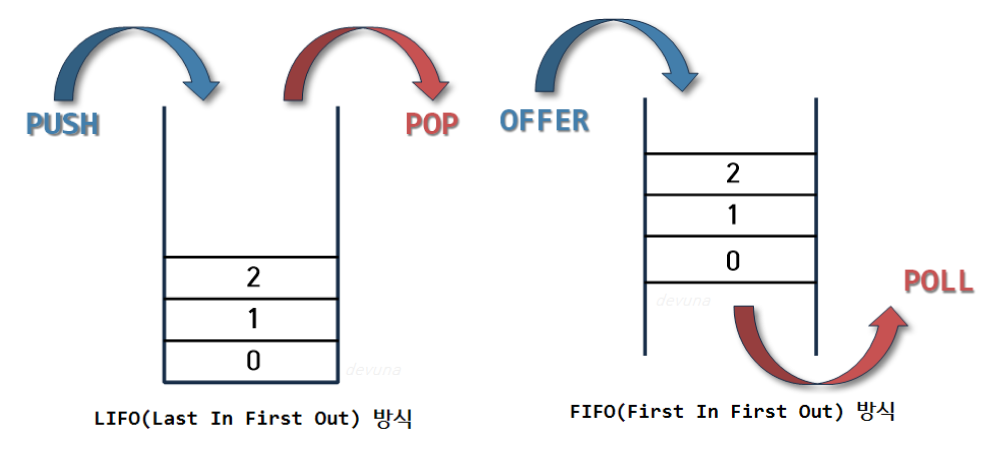
Stack (LIFO)
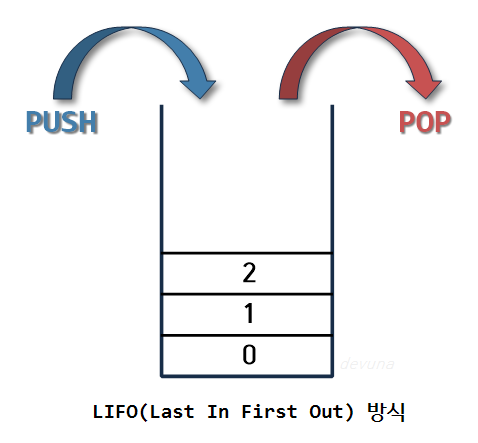
Stack의 개념
스택(Stack)이란?
쌓아 올린다는 것을 의미하며, 스택 자료 구조라는 것은 책을 쌓는 것처럼 차곡차곡 쌓아 올린 형태의 자료 구조를 말한다.
Stack의 특징
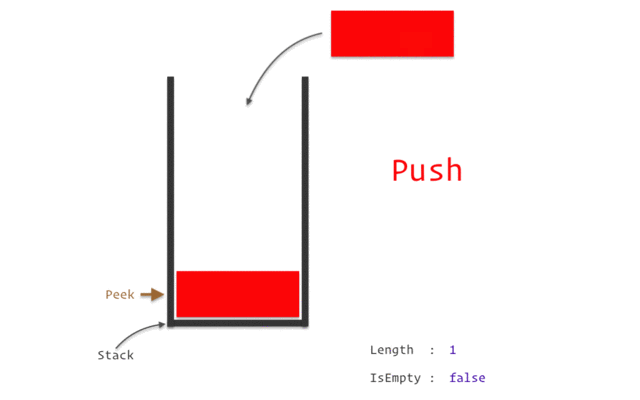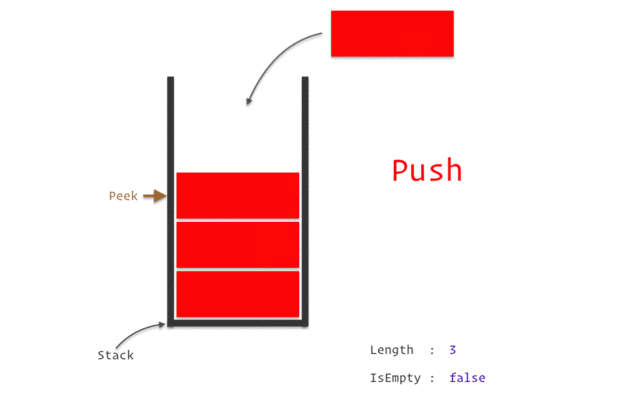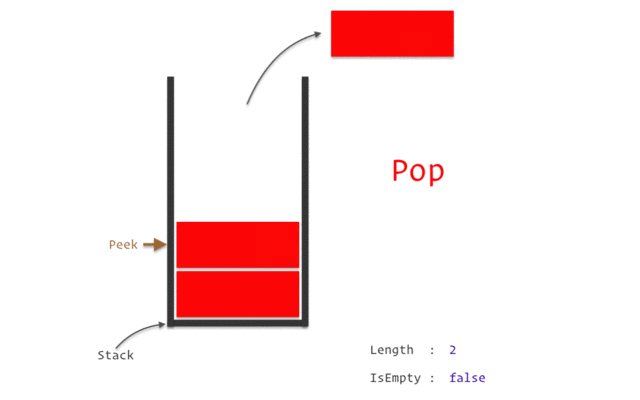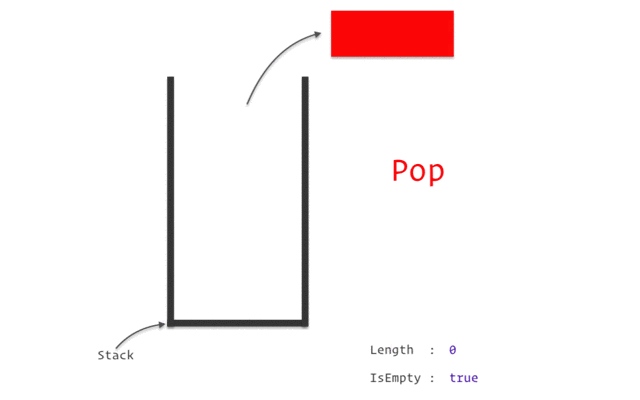
스택은 위의 이미지와 같이 구조와 크기의 자료를 정해진 방향으로만 쌓을 수 있고, Top으로 정한 곳을 통해서만 접근할 수 있다.
Top의 가장 위에 있는 자료는 가장 최근에 들어온 자료를 가리키고 있으며, 삽입되는 새 자료는 Top이 가리키는 자료의 위에 쌓인다.
스택에서 자료를 삭제할 때도 Top을 통해서만 가능하며, 스택에서의 Top을 통해 삽입하는 연산을 push, Top을 통한 삭제하는 연산을 pop이라고 한다.
따라서 스택은 시간 순서에 따라 자료가 쌓여서 가장 마지막에 삽입된 자료가 가장 먼저 삭제되는 후입선출(LIFO, Last-In-First-Out)의 구조를 갖고 있다.
비어있는 스택에서 원소를 추출하려는 경우를 stack underflow라고 하며, 스택이 넘치는 경우를 stack overflow라고 한다.
여기서 유래된 사이트가 바로 Stack Overflow 사이트이다.
왠지 의미를 유추하자면, 최신 기술 스택을 쌓아 올리고, 최신 기술을 뽑아내서 쓰고 하는 코딩계의 지식인 느낌으로 지은 듯
Stack의 활용
스택의 특징인 후입선출을 활용하여 여러 분야에서 활용이 가능한데,
- 웹 브라우저 방문 기록 (뒤로 가기) : 가장 나중에 열린 페이지부터 다시 보여줌
- 역순 문자열 만들기 : 가장 나중에 입려된 문자부터 출력
- 실행 취소 (undo) : 가장 나중에 입력된 문자부터 출력
- 후위 표기법 계산
- 수식의 괄호 검사 : 연산자 우선 순위 표현을 위한 괄호 검사
등의 활용 방안이 있다.
Stack의 장점
- 구현이 간단하고, 메모리를 효율적으로 사용할 수 있다.
- 접근 시간이 매우 빠르며, $O(1)$의 시간 복잡도를 갖는다.
- 재귀 알고리즘 등에 활용할 수 있다.
- 함수의 호출 스택, 웹 브라우저 방문 기록 등 다양한 분야에서 활용된다.
Stack의 단점
- 크기가 고정되어 있지 않아서 동적으로 메모리를 할당하는 경우에는 메모리를 할당 해제하는 과정이 빈번해질 수 있어, 비효율이다.
- 배열로 구현할 경우, 삽입/삭제 연산이 맨 앞에 위치할 때, 모든 원소의 위치를 옮겨줘야 하는 단점이 있다.
- 이 경우, $O(n)$의 시간 복잡도를 가지게 되는데, 이를 해결하기 위해 링크드 리스트로 구현할 수 있다.
- 후입선출(
LIFO)의 특성 때문에, 선입선출(FIFO)이나 우선순위 큐와 같은 다른 자료 구조와는 다르게, 특정 문제를 해결하기 어려울 수 있다.
Queue (FIFO)
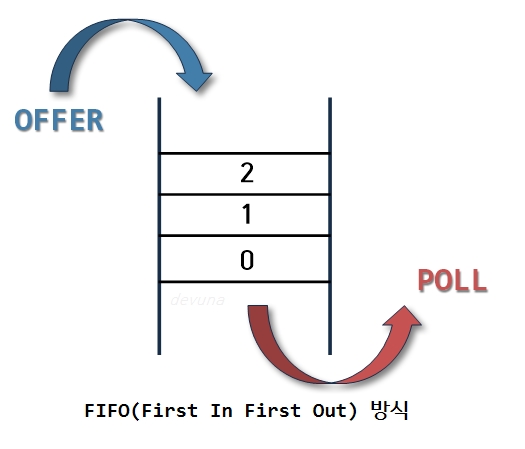
Queue의 개념
큐(Queue)란?
사전적인 의미로는 (무엇을 기다리는 사람, 자동차 등의) 줄, 혹은 줄을 서서 기다리는 것을 의미하며, 일상 생활에서 줄을 서서 기다리거나, 먼저 온 사람의 업무를 처리해주는 것과 같이 선입선출(FIFO, First-In-First-Out) 방식의 자료 구조를 말한다.
Queue의 특징
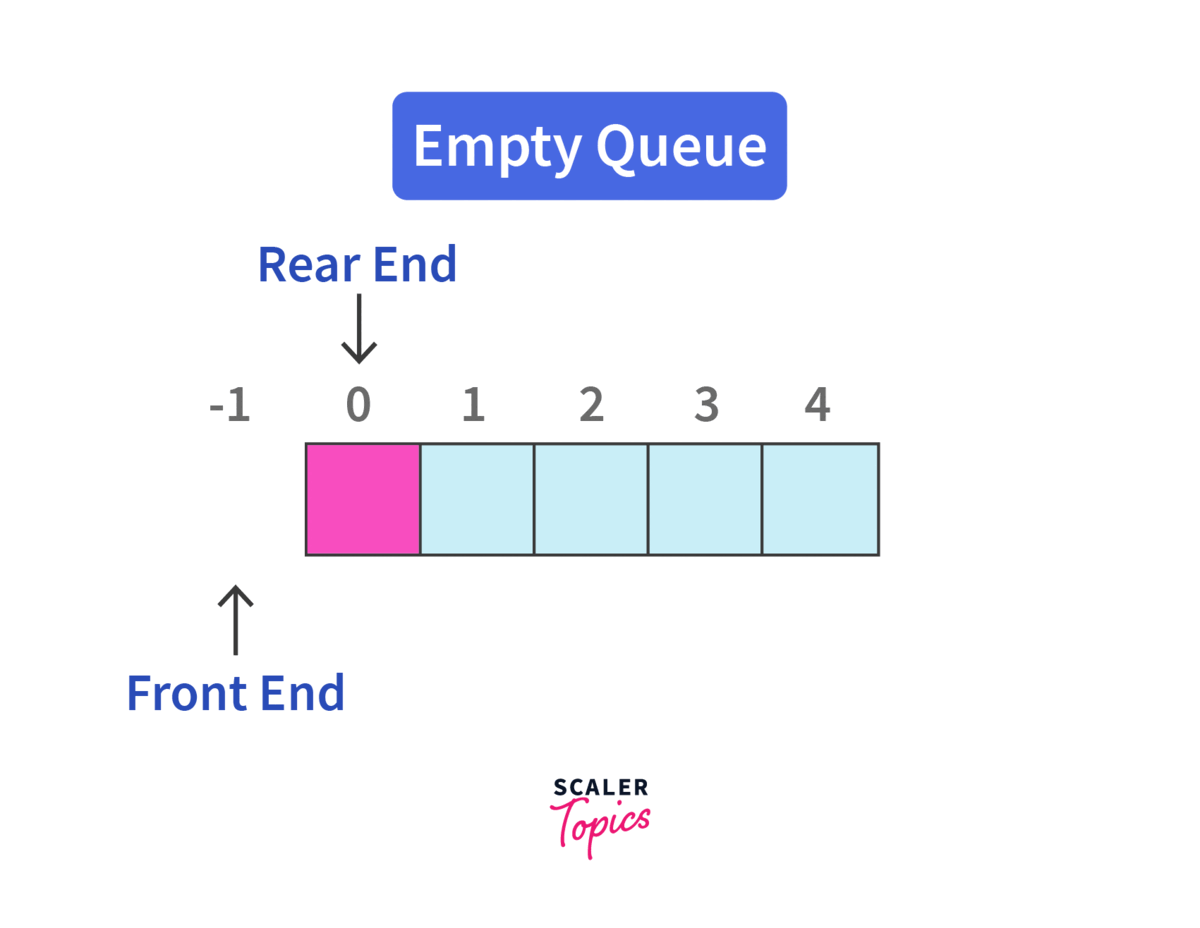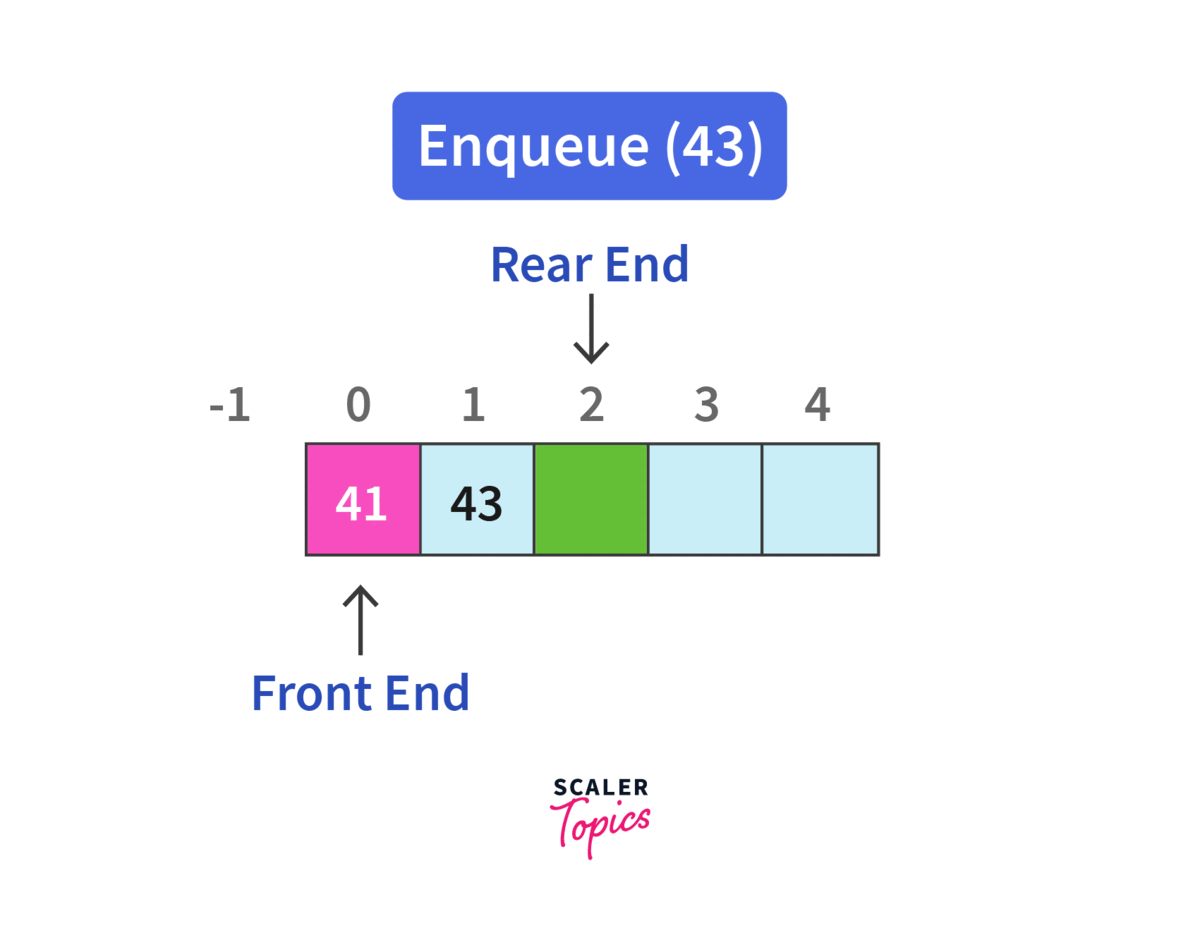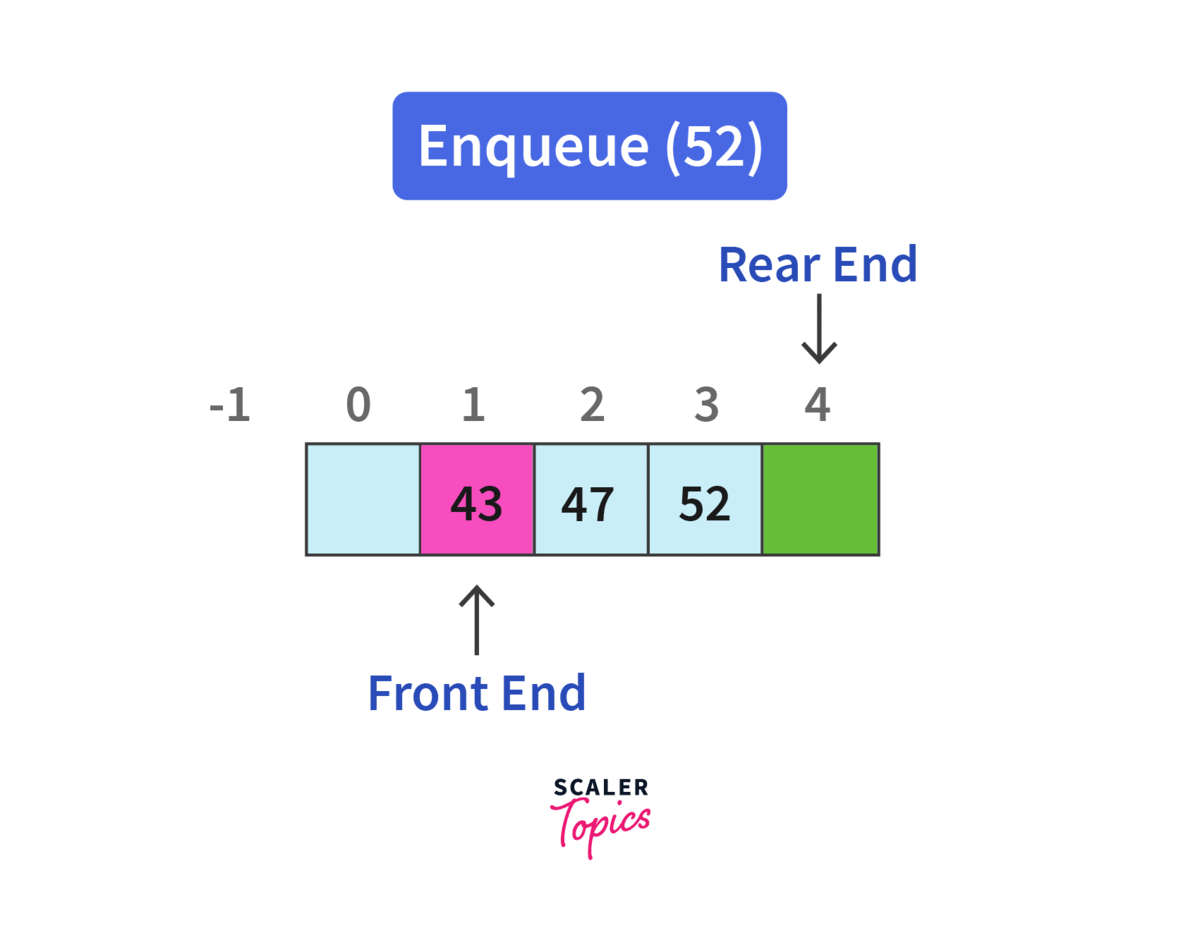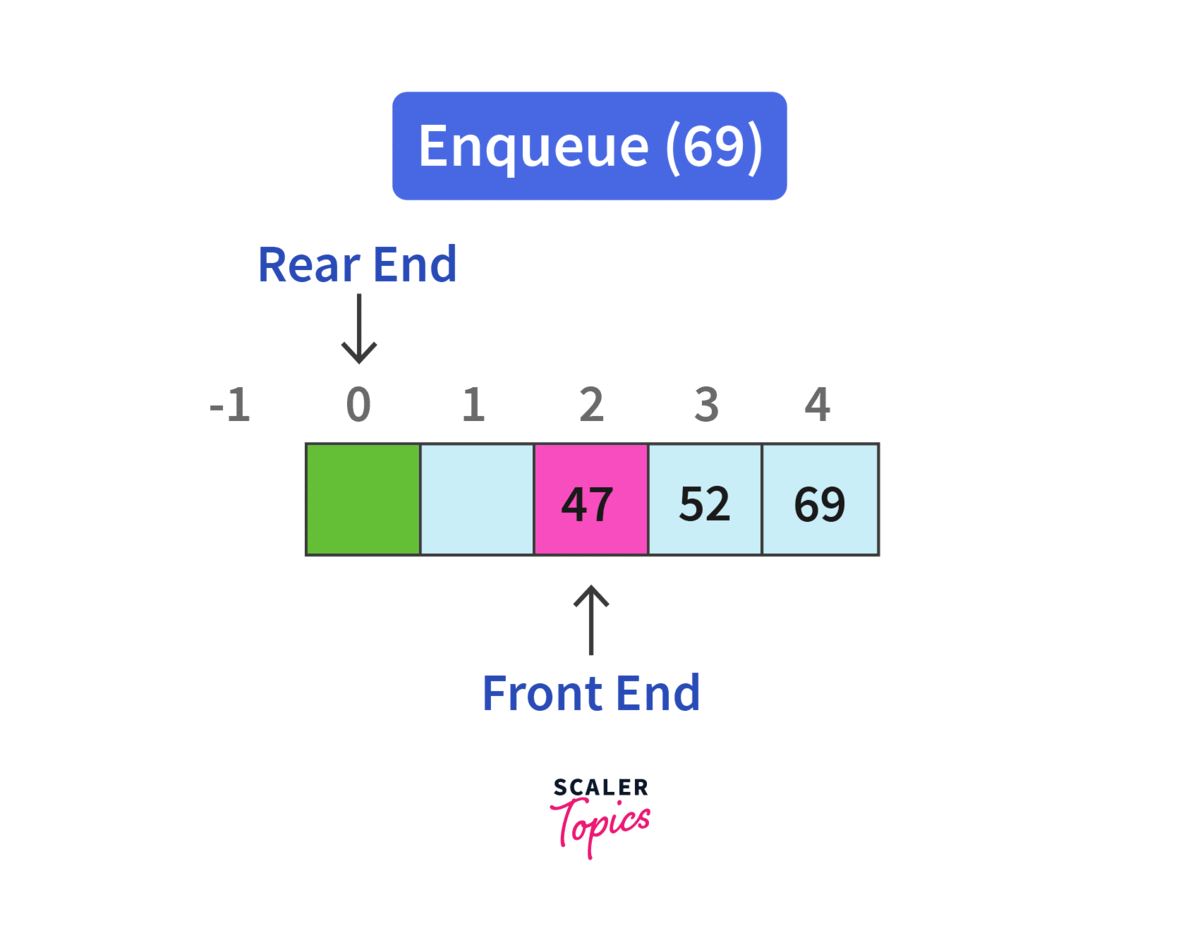
정해진 한 곳(Top)을 통해서 삽입, 삭제가 이루어지는 스택과는 달리, 큐는 한 쪽 끝에서 삽입 작업이, 다른 쪽 끝에서는 삭제 작업이 양 쪽으로 이루어진다.
이 때, 삭제 연산만 수행되는 곳을 프론트(Front), 삽입 연산만 이루어지는 곳을 리어(Rear)로 정하여 각각의 연산 작업만 수행된다.
여기서 큐의 리어(Rear)에서 이루어지는 삽입 연산을 인큐(EnQueue), 프론트(Front)에서 이루어지는 삭제 연산을 디큐(DeQueue)라고 한다.
- 큐의 가장 첫 원소를
Front/ 가장 끝 원소를Rear - 큐는 들어올 때
Rear로 들어오지만 나올 때는Front부터 빠지는 특성 - 접근은 가장 첫 원소와 끝 원소로만 가능
- 가장 먼저 들어온 프론트 원소가 가장 먼저 삭제
즉, 큐에서 프론트 원소는 가장 먼저 큐에 들어왔던 첫 번째 원소가 되는 것이며, 리어 원소는 가장 늦게 큐에 들어온 마지막 원소가 된다.
Queue의 활용
큐는 주로 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있는 상황에 이용한다.
- 우선 순위가 같은 작업 예약 (프린터의 인쇄 대기열)
- 은행 업무
- 콜센터 고객 대기시간
- 프로세스 관리
- 너비 우선 탐색(
BFS, Breadth-First Search) 알고리즘 구현 - 캐시(
Cache) 구현
Queue의 장점
- 선입선출 원칙에 따라 데이터 처리가 공정하고, 데이터 누락이나 중복 없이 처리된다.
- 구현이 간단하고, 데이터 삽입 및 삭제 시간 복잡도가 $O(1)$이므로 빠른 처리가 가능하다.
- 우선 순위 큐를 이용하면 정렬된 데이터 처리가 용이하다.
Queue의 단점
- 큐에 저장된 모든 데이터를 순회하면서 특정 데이터를 찾아내는 것은 비효율적이다.
- 큐에 데이터가 쌓이면, 메모리 사용량이 늘어나는 단점이 있다.
- 우선 순위 큐를 이용할 때는 구현 방식에 따라 힙 구조를 이용하는 등, 추가적인 구현이 필요할 수 있다.